Utiliza Mahout para un análisis de datos potente y efectivo
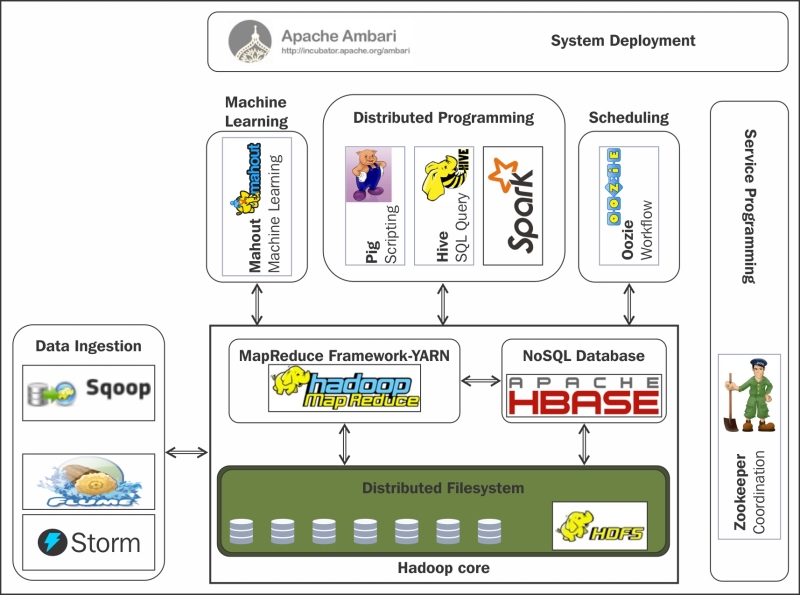
Mahout es una biblioteca de aprendizaje automático de código abierto que se utiliza para el análisis de datos a gran escala. Con Mahout, los desarrolladores pueden procesar grandes volúmenes de información y extraer conocimientos valiosos mediante técnicas de aprendizaje automático, minería de datos y análisis de texto. Esta herramienta se ha vuelto muy popular en la industria debido a su capacidad para manejar problemas de análisis de datos complejos y masivos.
Exploraremos cómo utilizar Mahout para realizar un análisis de datos potente y efectivo. Veremos los conceptos básicos de la biblioteca, aprenderemos cómo procesar datos y aplicar algoritmos de aprendizaje automático, y descubriremos cómo interpretar y visualizar los resultados obtenidos. Si estás interesado en mejorar tus habilidades de análisis de datos y aprender sobre una herramienta poderosa y versátil, sigue leyendo para descubrir todo lo que Mahout tiene para ofrecer.
- Cuáles son los fundamentos básicos de Mahout y cómo se utiliza en el análisis de datos
- Cuáles son las ventajas principales de utilizar Mahout en comparación con otras herramientas de análisis de datos
- Cómo puedes aprovechar Mahout para realizar recomendaciones personalizadas basadas en patrones de comportamiento
- Qué algoritmos de aprendizaje automático ofrece Mahout y cómo se aplican en el análisis de datos
- Cómo puedes utilizar Mahout para analizar grandes volúmenes de datos y obtener resultados rápidos y precisos
- Cuáles son las mejores prácticas para utilizar Mahout en un entorno de producción y asegurar la calidad de los resultados del análisis de datos
- Existen casos de uso específicos en los que Mahout ha demostrado ser especialmente efectivo en el análisis de datos
- Cuáles son las limitaciones o desafíos que podrías enfrentar al utilizar Mahout en el análisis de datos y cómo superarlos
- Qué recursos o documentación están disponibles para aprender a utilizar Mahout de manera efectiva en el análisis de datos
- Qué consideraciones de infraestructura debes tener en cuenta al utilizar Mahout para un análisis de datos potente y efectivo
- Preguntas frecuentes (FAQ)
Cuáles son los fundamentos básicos de Mahout y cómo se utiliza en el análisis de datos
Mahout es una librería de machine learning que se utiliza comúnmente para el análisis de datos. Entre sus fundamentos básicos se encuentran los algoritmos de clustering, clasificación, recomendación y filtrado colaborativo.
Para utilizar Mahout en el análisis de datos, se deben seguir algunos pasos. En primer lugar, es necesario importar la librería en el proyecto. Luego, se deben cargar los datos en un formato adecuado, como un archivo CSV o una base de datos.
A continuación, se pueden aplicar los algoritmos de Mahout a los datos. Por ejemplo, si se desea realizar un análisis de clustering, se puede utilizar el algoritmo K-means para agrupar los datos en diferentes clusters.
Una vez que se han aplicado los algoritmos, se pueden evaluar los resultados y visualizarlos de manera gráfica. Mahout ofrece herramientas para realizar estas tareas, como la generación de gráficos y la evaluación de la precisión de los modelos.
Mahout es una herramienta poderosa y efectiva para el análisis de datos. Su uso requiere de algunos conocimientos básicos de machine learning y programación, pero una vez que se domina, puede ser de gran utilidad en la extracción de información y la toma de decisiones basadas en datos.
Cuáles son las ventajas principales de utilizar Mahout en comparación con otras herramientas de análisis de datos
Mahout es una herramienta de análisis de datos que ofrece numerosas ventajas en comparación con otras herramientas similares. Una de las principales ventajas es su capacidad para manejar grandes volúmenes de datos de manera eficiente. Mahout utiliza algoritmos de procesamiento distribuido, lo que le permite procesar datos a gran escala en clústeres de computadoras.
Otra ventaja es su facilidad de uso. Mahout proporciona una interfaz intuitiva y amigable que permite a los usuarios realizar análisis de datos sin la necesidad de tener conocimientos avanzados en programación o estadísticas. Esto hace que Mahout sea accesible para usuarios de diferentes niveles de habilidad.
Mahout también se destaca por su amplia gama de algoritmos de aprendizaje automático. Estos algoritmos pueden ser utilizados para tareas como clasificación, clusterización, recomendación y filtrado colaborativo, entre otros. Esto hace que Mahout sea una herramienta versátil que puede adaptarse a diferentes casos de uso en análisis de datos.
Otra ventaja importante de Mahout es su integración con el ecosistema de Apache Hadoop. Esto permite aprovechar todas las capacidades de Hadoop, como el almacenamiento distribuido y el procesamiento paralelo, para mejorar el rendimiento y la escalabilidad de los análisis de datos realizados con Mahout.
Mahout ofrece ventajas significativas en términos de capacidad de manejo de datos, facilidad de uso, variedad de algoritmos de aprendizaje automático y su integración con Apache Hadoop. Estas ventajas hacen de Mahout una excelente opción para aquellos que buscan realizar análisis de datos potentes y efectivos.
Cómo puedes aprovechar Mahout para realizar recomendaciones personalizadas basadas en patrones de comportamiento
Mahout es una poderosa biblioteca de aprendizaje automático distribuido que te permite aprovechar patrones de comportamiento para realizar recomendaciones personalizadas. Puedes utilizar Mahout para analizar grandes conjuntos de datos y encontrar similitudes entre usuarios o productos.
Una de las características más destacadas de Mahout es su capacidad para trabajar con datos dispersos, lo que significa que puede manejar fácilmente conjuntos de datos con muchos valores faltantes. Esto es especialmente útil en aplicaciones de recomendación, donde es común que un usuario solo haya evaluado o comprado un subconjunto de elementos disponibles.
Para utilizar Mahout en tu análisis de datos, necesitarás tener conocimientos básicos de programación y estar familiarizado con conceptos de aprendizaje automático como algoritmos de agrupación y filtrado colaborativo.
El proceso paso a paso para utilizar Mahout en tu análisis de datos
- Preparación de los datos: antes de comenzar a utilizar Mahout, debes asegurarte de tener tus datos en un formato adecuado. Puedes utilizar herramientas como Apache Hadoop o Apache Spark para preprocesar tus datos y convertirlos en el formato requerido por Mahout.
- Selección del algoritmo: Mahout ofrece una amplia gama de algoritmos de aprendizaje automático que puedes utilizar para realizar diferentes tareas de análisis de datos, como clustering, clasificación y recomendación. Debes seleccionar el algoritmo que mejor se adapte a tus necesidades y datos.
- Entrenamiento del modelo: una vez que hayas seleccionado el algoritmo, deberás entrenar tu modelo utilizando tus datos. Esto implica proporcionar a Mahout los datos de entrada y configurar los parámetros del algoritmo.
- Evaluación del modelo: después de entrenar el modelo, debes evaluar su rendimiento utilizando métricas de calidad, como precisión y recall. Esto te ayudará a determinar si el modelo es adecuado para tu problema específico y si necesita ajustes adicionales.
- Generación de recomendaciones o resultados: una vez que hayas evaluado y ajustado tu modelo, puedes utilizarlo para generar recomendaciones o resultados basados en nuevos datos de entrada. Mahout proporciona funciones fáciles de usar para realizar estas tareas.
Mahout es una herramienta poderosa y efectiva para realizar análisis de datos y recomendaciones personalizadas. Siguiendo el proceso paso a paso mencionado anteriormente, puedes aprovechar al máximo esta biblioteca de aprendizaje automático distribuido y obtener información valiosa a partir de tus datos.
Qué algoritmos de aprendizaje automático ofrece Mahout y cómo se aplican en el análisis de datos
Mahout ofrece una amplia gama de algoritmos de aprendizaje automático que se pueden utilizar en el análisis de datos. Estos algoritmos están diseñados para facilitar la tarea de extraer información valiosa de grandes conjuntos de datos.
Algunos de los algoritmos más populares que ofrece Mahout incluyen el algoritmo de vecinos más cercanos, la regresión lineal, la clasificación bayesiana y los árboles de decisión. Estos algoritmos se pueden aplicar a una variedad de problemas de análisis de datos, como la clasificación de documentos, la recomendación de productos y la segmentación de clientes.
Algoritmo de vecinos más cercanos
- El algoritmo de vecinos más cercanos es un algoritmo de clasificación que se basa en encontrar los vecinos más cercanos a un punto de datos dado y asignarle la etiqueta más común entre esos vecinos.
- Este algoritmo se utiliza comúnmente en problemas de clasificación donde se necesita asignar una etiqueta a un nuevo punto de datos basado en las características de los puntos de datos existentes en el conjunto de entrenamiento.
Regresión lineal
- La regresión lineal es un algoritmo de aprendizaje automático supervisado que se utiliza para predecir el valor de una variable continua basada en la relación lineal entre las variables predictoras y la variable objetivo.
- Este algoritmo se utiliza comúnmente en problemas de regresión donde se necesita predecir un valor numérico, como el precio de una casa basado en variables como el tamaño, la ubicación y el número de habitaciones.
Clasificación bayesiana
- La clasificación bayesiana es un algoritmo de aprendizaje automático que se basa en el teorema de Bayes para asignar probabilidades a diferentes clases basadas en las características de los puntos de datos.
- Este algoritmo se utiliza comúnmente en problemas de clasificación donde se necesita asignar una etiqueta a un nuevo punto de datos basado en las probabilidades de las clases dadas las características observadas.
Árboles de decisión
- Los árboles de decisión son algoritmos de aprendizaje automático supervisado que se utilizan para tomar decisiones basadas en una serie de reglas de decisión.
- Estos árboles se construyen dividiendo el conjunto de datos en subconjuntos más pequeños basados en las características de los puntos de datos. Cada división se realiza de manera que maximice la pureza de los subconjuntos resultantes.
Estos son solo algunos ejemplos de los algoritmos de aprendizaje automático que Mahout ofrece para el análisis de datos. Cada algoritmo tiene sus propias ventajas y desventajas, por lo que es importante elegir el algoritmo adecuado para el problema específico que se está abordando.
Cómo puedes utilizar Mahout para analizar grandes volúmenes de datos y obtener resultados rápidos y precisos
Mahout es una poderosa herramienta de análisis de datos que te permite procesar grandes volúmenes de información de manera eficiente. Con su amplia variedad de algoritmos y funciones, Mahout te brinda la capacidad de extraer información valiosa de tus datos y tomar decisiones informadas.
Una de las ventajas de utilizar Mahout es su capacidad para trabajar con datos no estructurados, como texto, imágenes y videos. Esto te permite aplicar técnicas de análisis de texto, clasificación de imágenes y recomendación de videos, entre otros.
Algoritmos de aprendizaje automático
Mahout ofrece una amplia gama de algoritmos de aprendizaje automático, como clasificación, regresión y agrupamiento. Estos algoritmos pueden ser utilizados para identificar patrones, predecir resultados y segmentar tus datos en grupos similares.
Los algoritmos de clasificación son especialmente útiles para etiquetar datos, como por ejemplo, clasificar correos electrónicos como spam o no spam. Los algoritmos de regresión te permiten predecir valores numéricos, como el precio de una casa en función de sus características.
Los algoritmos de agrupamiento agrupan los datos en función de la similitud entre ellos. Esto puede ser útil para segmentar tus clientes en diferentes grupos con el fin de personalizar tus estrategias de marketing.
Recomendaciones personalizadas
Otra característica destacada de Mahout es su capacidad para generar recomendaciones personalizadas. Esto es especialmente útil en aplicaciones como la recomendación de productos en un sitio de comercio electrónico.
Utilizando algoritmos de recomendación, Mahout analiza los datos de los usuarios, como sus preferencias y comportamientos de compra, y genera recomendaciones de productos que se ajusten a sus intereses individuales. Esto puede ayudarte a aumentar las ventas y la satisfacción del cliente.
Escala y rendimiento
Mahout está diseñado para manejar grandes volúmenes de datos de manera eficiente. Utiliza tecnologías como Apache Hadoop y Apache Spark para distribuir el procesamiento de datos en clústeres de máquinas, lo que te permite procesar grandes conjuntos de datos de manera rápida y escalable.
Además, Mahout aprovecha el potencial de la programación paralela para acelerar el análisis de datos. Esto significa que puedes obtener resultados rápidos sin comprometer la precisión de tus análisis.
Mahout es una herramienta poderosa para el análisis de datos que te permite procesar grandes volúmenes de información de manera eficiente. Sus algoritmos de aprendizaje automático, capacidad de recomendación personalizada y rendimiento escalable la convierten en una opción ideal para empresas y organizaciones que desean aprovechar al máximo sus datos.
Cuáles son las mejores prácticas para utilizar Mahout en un entorno de producción y asegurar la calidad de los resultados del análisis de datos
Mahout es una biblioteca de aprendizaje automático distribuido que ofrece una amplia gama de algoritmos para análisis de datos. Sin embargo, para obtener resultados precisos y confiables, es importante seguir algunas mejores prácticas al utilizar Mahout en un entorno de producción.
1. Preprocesamiento de datos
Antes de utilizar Mahout para el análisis de datos, es esencial realizar un adecuado preprocesamiento de los datos. Esto implica la limpieza de los datos, la eliminación de valores atípicos y la normalización de las variables. Un preprocesamiento correcto asegurará que los datos sean aptos para el análisis y minimizará la posibilidad de obtener resultados incorrectos.
2. Selección de algoritmos adecuados
Mahout ofrece diversos algoritmos de aprendizaje automático, cada uno con sus propias fortalezas y limitaciones. Es importante comprender los requisitos y las características de los datos y seleccionar el algoritmo más adecuado para el análisis. Esto garantizará que los resultados sean precisos y útiles para la toma de decisiones.
3. Configuración de parámetros
Los algoritmos de Mahout suelen tener parámetros ajustables que afectan el rendimiento y la calidad de los resultados. Es importante configurar correctamente estos parámetros según las necesidades del análisis y los datos disponibles. Una configuración inadecuada puede llevar a resultados poco confiables o incluso a errores en el análisis.
4. Validación y evaluación
Después de realizar el análisis de datos con Mahout, es crucial validar y evaluar los resultados obtenidos. Esto implica comparar los resultados con datos de prueba o utilizar técnicas de validación cruzada para evaluar la precisión del modelo. La validación y evaluación adecuadas ayudarán a identificar posibles problemas y mejorar la calidad de los resultados.
5. Escalabilidad y rendimiento
Uno de los principales beneficios de Mahout es su capacidad para realizar análisis de datos a gran escala. Sin embargo, para garantizar un rendimiento óptimo, es importante diseñar una arquitectura adecuada, distribuir los datos de manera eficiente y utilizar técnicas de paralelismo. Esto asegurará que el análisis sea rápido y eficiente, incluso con grandes conjuntos de datos.
Al utilizar Mahout para el análisis de datos en un entorno de producción, es esencial seguir estas mejores prácticas. El preprocesamiento adecuado de los datos, la selección correcta de algoritmos, la configuración de parámetros, la validación y evaluación, y la consideración de la escalabilidad y el rendimiento son fundamentales para obtener resultados precisos y confiables. Siguiendo estas pautas, podrás utilizar Mahout de manera efectiva y obtener información valiosa de tus datos.
Existen casos de uso específicos en los que Mahout ha demostrado ser especialmente efectivo en el análisis de datos
Mahout es una biblioteca de aprendizaje automático distribuida que puede ser utilizada para una variedad de casos de uso en el análisis de datos. Algunos de estos casos de uso específicos incluyen la clasificación de documentos, la generación de recomendaciones y el análisis de agrupamiento.
En el caso de la clasificación de documentos, Mahout puede ayudar a los usuarios a categorizar automáticamente grandes cantidades de documentos en diferentes temas o etiquetas. Esto puede resultar especialmente útil en industrias como la prensa, donde se generan grandes volúmenes de contenido diariamente.
Otro caso de uso donde Mahout brilla es en la generación de recomendaciones, donde puede ayudar a los usuarios a tomar decisiones informadas basadas en patrones de comportamiento y preferencias. Esto puede ser utilizado por plataformas de comercio electrónico para realizar recomendaciones de productos personalizadas a sus clientes.
Además, Mahout también puede ser utilizado para realizar análisis de agrupamiento, lo que implica agrupar datos similares en diferentes categorías. Esto puede ser útil en ciencia de datos, donde se pueden identificar patrones ocultos en grandes conjuntos de datos y realizar agrupamientos basados en características similares.
En general, Mahout ofrece una amplia gama de funcionalidades para el análisis de datos y puede ser utilizado en una variedad de industrias y sectores. Su distribución y capacidad de escalar en clústeres de computadoras lo convierten en una herramienta poderosa y efectiva para el análisis de datos a gran escala.
Cuáles son las limitaciones o desafíos que podrías enfrentar al utilizar Mahout en el análisis de datos y cómo superarlos
Al utilizar Mahout en el análisis de datos, es importante tener en cuenta algunas limitaciones y desafíos que podrían surgir. Uno de los principales desafíos es la necesidad de contar con un conjunto de datos de gran tamaño para obtener resultados significativos. Mahout está diseñado para trabajar con grandes volúmenes de datos, por lo que si tus datos son limitados, es posible que los resultados no sean tan precisos.
Otro desafío puede ser la complejidad de la implementación de algoritmos específicos. Mahout ofrece una amplia gama de algoritmos de análisis, pero cada uno tiene sus propias configuraciones y requisitos. Es importante comprender adecuadamente cómo funcionan estos algoritmos y cuándo utilizarlos de manera efectiva para obtener resultados precisos.
Además, la capacidad de procesamiento y recursos del sistema también pueden ser un desafío. El análisis de datos a gran escala puede requerir una gran cantidad de recursos de hardware y almacenamiento, por lo que es importante asegurarse de tener un sistema lo suficientemente potente para ejecutar Mahout de manera eficiente.
Para superar estas limitaciones y desafíos, es esencial tener una comprensión sólida de Mahout y sus capacidades. Es recomendable realizar una investigación exhaustiva sobre los algoritmos disponibles y cómo se pueden aplicar a tus datos específicos. Además, es importante optimizar el rendimiento del sistema y garantizar que haya suficiente capacidad de almacenamiento disponible.
Aunque Mahout ofrece un análisis de datos potente y efectivo, es importante tener en cuenta las limitaciones y desafíos asociados. Al comprender y superar estos desafíos, puedes aprovechar al máximo esta herramienta y obtener resultados precisos en tus análisis de datos.
Qué recursos o documentación están disponibles para aprender a utilizar Mahout de manera efectiva en el análisis de datos
Mahout es una poderosa biblioteca de aprendizaje automático que se utiliza para el análisis de datos a gran escala. Si estás interesado en aprender a utilizar Mahout de manera efectiva, hay varios recursos y documentación disponibles para ayudarte en tu proceso de aprendizaje.
En primer lugar, puedes consultar la documentación oficial de Mahout. Esta documentación proporciona una guía detallada sobre cómo instalar y configurar Mahout, así como también explica los diversos algoritmos y técnicas disponibles en la biblioteca. También encontrarás ejemplos de código y casos de uso comunes para ayudarte a entender cómo utilizar Mahout en situaciones reales.
Otra buena opción es explorar los tutoriales y ejemplos en línea. Hay muchos recursos disponibles en blogs, foros y sitios web especializados en aprendizaje automático y análisis de datos. Estos recursos proporcionan ejemplos prácticos y explicaciones paso a paso sobre cómo utilizar Mahout en diferentes escenarios.
Además de la documentación oficial y los recursos en línea, también puedes considerar unirte a grupos y comunidades de Mahout. Hay grupos en línea donde puedes hacer preguntas, obtener ayuda de expertos y compartir tus experiencias con otros usuarios de Mahout. Al interactuar con otros profesionales y entusiastas de Mahout, podrás aprender de sus conocimientos y obtener consejos prácticos para utilizar Mahout de manera efectiva en tus proyectos.
Por último, no te olvides de los libros dedicados a Mahout y al aprendizaje automático en general. Estos libros pueden proporcionarte una visión más profunda sobre los conceptos y técnicas detrás de Mahout, así como también ofrecer ejemplos prácticos y estudios de caso. Algunos libros recomendados son "Mahout in Action" de Sean Owen, Robin Anil, y Ted Dunning, y "Machine Learning with Mahout" de Sameer Wadkar.
Hay una gran cantidad de recursos y documentación disponibles para aprender a utilizar Mahout de manera efectiva en el análisis de datos. Ya sea a través de la documentación oficial, los tutoriales y ejemplos en línea, los grupos y comunidades, o los libros especializados, puedes encontrar toda la información que necesitas para dominar Mahout y aprovechar al máximo sus capacidades en tus proyectos de análisis de datos.
Qué consideraciones de infraestructura debes tener en cuenta al utilizar Mahout para un análisis de datos potente y efectivo
Cuando decides utilizar Mahout para realizar un análisis de datos potente y efectivo, es importante tener en cuenta algunas consideraciones de infraestructura para asegurar un rendimiento óptimo.
1. Elige adecuadamente tu hardware:
Dependiendo del tamaño de tus datos y de la complejidad de tus algoritmos, es importante seleccionar un hardware que pueda manejar eficientemente el procesamiento intensivo de datos. Considera aspectos como la cantidad de almacenamiento, la cantidad de RAM y la capacidad de procesamiento de tu hardware.
2. Configuración del clúster:
Si planeas utilizar Mahout en un entorno de clúster, es fundamental configurar de manera adecuada los nodos del clúster para que trabajen de manera eficiente. Asegúrate de definir correctamente el número de nodos, la asignación de recursos y la configuración de la red.
3. Optimiza el uso de recursos:
Para garantizar un análisis de datos potente y efectivo, es esencial optimizar el uso de los recursos disponibles. Esto incluye aprovechar al máximo la capacidad de procesamiento, la memoria y el almacenamiento, así como llevar a cabo tareas en paralelo y utilizar algoritmos de Mahout que se adapten a tus necesidades específicas.
4. Mantén tus datos organizados:
Antes de utilizar Mahout, asegúrate de tener tus datos organizados de manera adecuada. Esto implica eliminar datos irrelevantes o duplicados, asegurarte de que tus datos estén en el formato adecuado y dividir tus datos en conjuntos de entrenamiento y prueba para validar tus resultados.
5. Realiza pruebas y ajustes:
Antes de realizar un análisis completo de tus datos, es recomendable realizar pruebas y ajustes con conjuntos de datos más pequeños. Esto te permitirá identificar posibles problemas o cuellos de botella en tus algoritmos y realizar ajustes necesarios para obtener resultados más precisos y efectivos.
6. Realiza un seguimiento del rendimiento:
Una vez que empieces a utilizar Mahout para tu análisis de datos, es importante realizar un seguimiento del rendimiento de tus algoritmos. Esto te permitirá identificar posibles áreas de mejora y optimizar tu proceso de análisis para obtener resultados más rápidos y precisos.
Conclusión:
Al utilizar Mahout para un análisis de datos potente y efectivo, es esencial considerar aspectos de infraestructura como la elección adecuada del hardware, la configuración del clúster, la optimización de recursos, la organización de datos, las pruebas y ajustes, y el seguimiento del rendimiento. Al prestar atención a estas consideraciones, podrás aprovechar al máximo los beneficios que Mahout ofrece en el procesamiento y análisis de datos.
Preguntas frecuentes (FAQ)
1. ¿Qué es Mahout?
Mahout es una biblioteca de aprendizaje automático de código abierto que se utiliza para realizar análisis de datos y crear modelos predictivos.
2. ¿Cuáles son las principales características de Mahout?
Las principales características de Mahout son su capacidad de procesar grandes cantidades de datos, su implementación de algoritmos de aprendizaje automático y su facilidad de uso.
3. ¿Qué tipos de análisis de datos puedo realizar con Mahout?
Con Mahout, puedes realizar análisis de datos como recomendaciones de productos, clasificación de documentos, clustering de datos y detección de anomalías, entre otros.
4. ¿Qué lenguajes de programación son compatibles con Mahout?
Mahout está diseñado para trabajar con lenguajes de programación como Java y Scala, lo que permite una integración sencilla en proyectos existentes.
5. ¿Es Mahout adecuado para proyectos de todos los tamaños?
Sí, Mahout es adecuado para proyectos de todos los tamaños, desde pequeños conjuntos de datos hasta grandes cantidades de información. Además, su capacidad de procesamiento distribuido lo hace escalable y eficiente.
Deja una respuesta
Entradas relacionadas