Conecta Apache Mahout y MySQL fácilmente con JPA
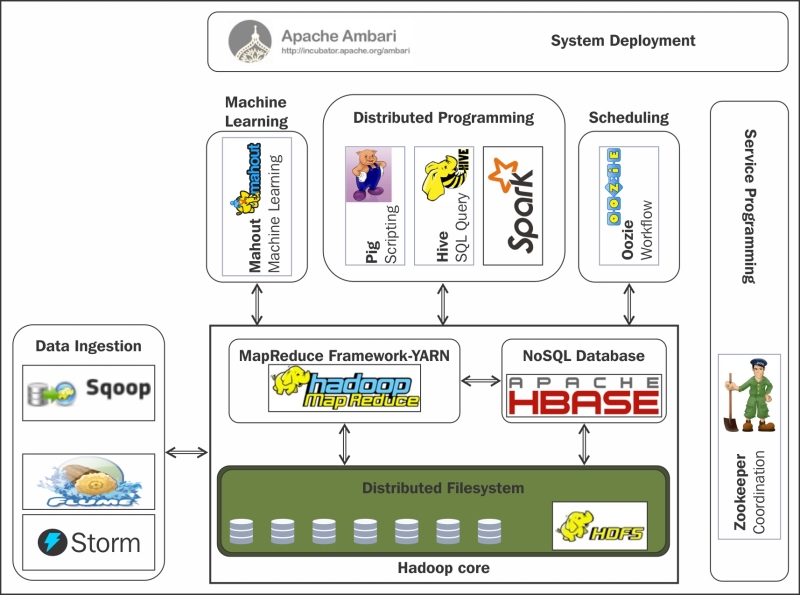
Apache Mahout es una biblioteca de aprendizaje automático que se utiliza para construir aplicaciones de análisis predictivo y personalización. Permite a los desarrolladores implementar algoritmos de aprendizaje automático en sus aplicaciones sin tener que escribir todo el código desde cero. Por otro lado, MySQL es un popular sistema de gestión de bases de datos utilizado por muchas empresas para almacenar y administrar grandes volúmenes de datos.
Exploraremos cómo conectar Apache Mahout y MySQL utilizando JPA (Java Persistence API). JPA es una especificación de Java que proporciona una interfaz de programación para interactuar con bases de datos relacionales. Veremos cómo configurar Mahout y MySQL en nuestro entorno de desarrollo, cómo utilizar JPA para conectarse a la base de datos y cómo realizar operaciones básicas como consultar, insertar y actualizar datos utilizando Mahout y JPA. ¡Vamos a sumergirnos en el mundo de la inteligencia artificial y las bases de datos!
- Qué es Apache Mahout y cuál es su función dentro de un proyecto de Machine Learning
- Cuáles son las ventajas de utilizar JPA para conectar Apache Mahout y MySQL
- Cómo instalar y configurar Apache Mahout en un proyecto Java
- Cuál es el proceso para establecer la conexión entre Apache Mahout y MySQL utilizando JPA
- Qué es JPA y cómo se utiliza para realizar operaciones CRUD en una base de datos MySQL
- Existen alternativas a JPA para conectar Apache Mahout y MySQL
- Cuáles son las mejores prácticas para optimizar el rendimiento al utilizar Apache Mahout y MySQL con JPA
- Qué tipos de consultas se pueden realizar utilizando JPA en un proyecto que combine Apache Mahout y MySQL
- Es posible utilizar Apache Mahout y MySQL sin utilizar JPA? ¿Cuáles serían las implicaciones
- Existen librerías o frameworks adicionales que se puedan utilizar en conjunto con Apache Mahout, MySQL y JPA para mejorar la experiencia de desarrollo
- Qué precauciones de seguridad se deben tener en cuenta al conectar Apache Mahout y MySQL utilizando JPA
Qué es Apache Mahout y cuál es su función dentro de un proyecto de Machine Learning
Apache Mahout es una biblioteca de aprendizaje automático de código abierto que proporciona algoritmos y herramientas para implementar técnicas de machine learning en proyectos de Big Data. Su objetivo principal es facilitar la implementación de algoritmos de aprendizaje automático en proyectos de procesamiento distribuido y paralelo.
La función de Apache Mahout dentro de un proyecto de Machine Learning es proporcionar un conjunto de algoritmos y herramientas que permiten realizar tareas de clasificación, clustering, recomendación y filtrado colaborativo, entre otras. Estos algoritmos se pueden utilizar para descubrir patrones y relaciones ocultas en grandes volúmenes de datos, lo que resulta fundamental para la toma de decisiones y la generación de insights en diferentes industrias.
La importancia de Apache Mahout radica en su capacidad para trabajar con grandes volúmenes de datos y su interoperabilidad con otras herramientas y tecnologías, como MySQL y JPA. Esto permite a los desarrolladores y científicos de datos aprovechar las capacidades de Mahout en combinación con otras tecnologías para construir sistemas de aprendizaje automático más potentes y escalables.
Apache Mahout es una biblioteca de aprendizaje automático de código abierto que proporciona algoritmos y herramientas para implementar técnicas de machine learning en proyectos de Big Data. Su función principal es permitir la implementación de algoritmos de aprendizaje automático en entornos distribuidos y paralelos, lo que facilita el descubrimiento de patrones y relaciones ocultas en grandes volúmenes de datos.
Cuáles son las ventajas de utilizar JPA para conectar Apache Mahout y MySQL
JPA, o Java Persistence API, es una especificación de Java que proporciona una interfaz para interactuar con bases de datos relacionales de manera más sencilla. Al utilizar JPA para conectar Apache Mahout, una biblioteca de aprendizaje automático, y MySQL, se obtienen varias ventajas.
En primer lugar, JPA permite abstraerse de los detalles de la base de datos subyacente y trabajar con entidades y objetos en Java. Esto facilita el desarrollo y el mantenimiento del código, ya que se puede utilizar una sintaxis orientada a objetos más familiar.
Otra ventaja es la capacidad de JPA para manejar la persistencia de los datos de manera automática. Esto significa que no es necesario escribir consultas SQL manuales para insertar, actualizar o eliminar registros en la base de datos. JPA se encarga de traducir las operaciones realizadas sobre las entidades en consultas SQL.
Además, JPA proporciona un mecanismo de cache para mejorar el rendimiento de las consultas. Esto significa que si se realiza una consulta y los resultados están en la cache, no es necesario acceder a la base de datos, lo que reduce la carga y mejora la velocidad de respuesta.
Otra ventaja es la capacidad de JPA para realizar consultas avanzadas utilizando el lenguaje JPQL (Java Persistence Query Language). Esto permite realizar consultas complejas utilizando una sintaxis similar a SQL, pero teniendo en cuenta la estructura de objetos en lugar de tablas y columnas.
Utilizar JPA para conectar Apache Mahout y MySQL proporciona ventajas en términos de desarrollo más sencillo, menor cantidad de código SQL manual, mejor rendimiento y capacidad de realizar consultas avanzadas utilizando JPQL.
Cómo instalar y configurar Apache Mahout en un proyecto Java
Para instalar y configurar Apache Mahout en un proyecto Java, primero debemos asegurarnos de tener Java Development Kit (JDK) instalado en nuestra máquina. Luego, descargamos el archivo binario de Mahout desde su página web oficial.
Una vez descargado, descomprimimos el archivo y configuramos las variables de entorno necesarias para que nuestro sistema reconozca la ubicación de Mahout. Esto se puede hacer modificando el archivo de configuración del sistema o utilizando un IDE como Eclipse.
A continuación, creamos un nuevo proyecto Java en nuestro IDE y agregamos la biblioteca de Mahout como una dependencia externa. Esto nos permitirá utilizar las funcionalidades de Mahout en nuestro proyecto.
Finalmente, podemos comenzar a utilizar Mahout en nuestro proyecto Java. Podemos importar las clases necesarias de Mahout y utilizar sus métodos para realizar tareas de minería de datos, recomendaciones o análisis de texto, entre otras funciones.
Con estos pasos simples, podemos instalar y configurar Apache Mahout en nuestro proyecto Java y aprovechar todas sus capacidades para la construcción de sistemas inteligentes y análisis de big data.
Cuál es el proceso para establecer la conexión entre Apache Mahout y MySQL utilizando JPA
El proceso para establecer la conexión entre Apache Mahout y MySQL utilizando JPA consta de varios pasos. En primer lugar, es necesario incluir las dependencias necesarias en el archivo pom.xml de nuestro proyecto Maven. Luego, debemos configurar el persistence.xml para establecer la conexión con la base de datos MySQL.
A continuación, debemos crear las entidades JPA que representarán las tablas de nuestra base de datos. Cada entidad debe tener las anotaciones adecuadas para mapearla correctamente con las columnas de la tabla correspondiente en MySQL.
Una vez que hemos creado las entidades, podemos utilizar el EntityManager para realizar operaciones CRUD en la base de datos. Por ejemplo, podemos utilizar el método persist para insertar nuevos registros, o el método merge para actualizar registros existentes.
Además de las operaciones CRUD básicas, también podemos utilizar JPA para realizar consultas más complejas utilizando el lenguaje de consultas de JPA (JPQL). Por ejemplo, podemos utilizar JPQL para realizar consultas de selección, filtrado, ordenamiento y agrupamiento de datos.
Utilizar JPA para establecer la conexión entre Apache Mahout y MySQL es un proceso relativamente sencillo que nos permite aprovechar todas las ventajas de ambos frameworks. Con JPA, podemos realizar operaciones CRUD en la base de datos de manera eficiente y realizar consultas complejas utilizando el poderoso lenguaje de consultas de JPA.
Qué es JPA y cómo se utiliza para realizar operaciones CRUD en una base de datos MySQL
JPA, o Java Persistence API, es una especificación de Java que proporciona un conjunto de interfaces para interactuar con bases de datos relacionales. Permite realizar operaciones CRUD (Crear, Leer, Actualizar, Eliminar) de manera fácil y eficiente.
Para utilizar JPA con MySQL, primero necesitamos configurar nuestra aplicación con la dependencia de JPA y el controlador de MySQL. Luego, creamos una entidad que represente una tabla en la base de datos y anotamos sus atributos con las correspondientes anotaciones de JPA.
Después de crear la entidad, podemos utilizar las operaciones CRUD proporcionadas por JPA para interactuar con la base de datos. Podemos crear nuevos registros, leer registros existentes, actualizar registros y eliminar registros, todo a través de métodos simples y expresivos.
Una vez que hayamos configurado nuestra aplicación y creado la entidad, JPA se encargará de generar las consultas SQL necesarias para realizar las operaciones CRUD en la base de datos MySQL. Esto nos permite abstraernos de los detalles de la implementación específica de MySQL y nos brinda la flexibilidad de cambiar a otro motor de base de datos en el futuro sin tener que modificar nuestra lógica de negocio.
JPA nos permite conectar fácilmente Apache Mahout con MySQL para realizar operaciones CRUD de manera eficiente y elegante. Al abstraernos de los detalles de implementación de la base de datos, podemos enfocarnos en el desarrollo de nuestra aplicación y aprovechar al máximo las funcionalidades que nos brinda JPA.
Existen alternativas a JPA para conectar Apache Mahout y MySQL
Mientras que JPA (Java Persistence API) es una opción popular para conectar Apache Mahout y MySQL, existen otras alternativas disponibles que pueden facilitar aún más el proceso. Una de estas alternativas es el uso de JDBC (Java Database Connectivity), que proporciona una interfaz más directa para interactuar con una base de datos relacional como MySQL.
Otra opción es utilizar Hibernate, un framework de mapeo objeto-relacional que también es compatible con Mahout y MySQL. Hibernate simplifica el proceso de persistencia de datos y proporciona un puente entre el modelo de objetos de Mahout y la base de datos relacional.
Además de JDBC y Hibernate, también se puede considerar el uso de MyBatis, otro framework de mapeo objeto-relacional que ofrece una solución más ligera y flexible. MyBatis permite un control más preciso sobre las consultas SQL y se puede utilizar de manera eficiente en combinación con Mahout y MySQL.
Aunque JPA es una opción confiable para conectar Apache Mahout y MySQL, existen alternativas como JDBC, Hibernate y MyBatis que pueden adaptarse mejor a las necesidades específicas de cada proyecto. La elección de la alternativa adecuada depende de factores como la complejidad del proyecto, el rendimiento requerido y las preferencias del desarrollador.
Cuáles son las mejores prácticas para optimizar el rendimiento al utilizar Apache Mahout y MySQL con JPA
La combinación de Apache Mahout, MySQL y JPA puede ser una poderosa herramienta para el análisis de datos y la generación de recomendaciones. Sin embargo, para aprovechar al máximo su potencial, es importante seguir algunas mejores prácticas para optimizar el rendimiento.
1. Establecer índices adecuados
Uno de los factores clave para mejorar el rendimiento es asegurarse de que las tablas de la base de datos estén correctamente indexadas. Esto permitirá una búsqueda y filtrado más eficiente de los datos, lo que resultará en consultas más rápidas.
2. Utilizar el caché de JPA
El caché de JPA es una excelente manera de mejorar el rendimiento al reducir la cantidad de consultas a la base de datos. Al almacenar en memoria los objetos que se acceden con frecuencia, se evita la necesidad de consultar la base de datos repetidamente, lo que puede ralentizar el proceso.
3. Optimizar consultas
Es importante asegurarse de que las consultas realizadas a la base de datos estén optimizadas para obtener los resultados deseados de manera eficiente. Esto implica utilizar índices, evitar consultas innecesarias o complejas, y utilizar consultas parametrizadas en lugar de concatenar valores directamente en la consulta.
4. Utilizar índice invertido de Mahout
Apache Mahout proporciona un índice invertido que puede ser utilizado para mejorar el rendimiento al buscar y recuperar datos. Este índice permite una búsqueda eficiente de palabras clave o términos en grandes volúmenes de datos, lo que puede ser especialmente útil en casos de análisis de texto o generación de recomendaciones basadas en contenido.
5. Optimizar la configuración del servidor de base de datos
Además de las optimizaciones específicas de Mahout y JPA, también es importante asegurarse de que la configuración del servidor de base de datos esté optimizada para el rendimiento. Esto puede incluir ajustar parámetros como la memoria asignada al servidor, el tamaño del caché y los límites de conexión simultánea.
6. Realizar pruebas de rendimiento
Una vez implementadas estas mejores prácticas, es importante realizar pruebas de rendimiento para evaluar la eficacia de las optimizaciones realizadas. Esto permitirá identificar posibles cuellos de botella y áreas de mejora adicionales.
Al seguir estas mejores prácticas, podrás optimizar el rendimiento al utilizar Apache Mahout y MySQL con JPA. Estas recomendaciones te ayudarán a obtener resultados más rápidos y eficientes en tus análisis de datos y generación de recomendaciones.
Qué tipos de consultas se pueden realizar utilizando JPA en un proyecto que combine Apache Mahout y MySQL
Utilizando JPA en un proyecto que combine Apache Mahout y MySQL, se pueden realizar diferentes tipos de consultas que permiten obtener información específica de la base de datos. Entre estas consultas se encuentran:
- Consultas de selección: permiten obtener datos de una o varias tablas en la base de datos. Estas consultas pueden ser simples, utilizando la cláusula SELECT, o más complejas, utilizando cláusulas como JOIN, WHERE o GROUP BY.
- Consultas de inserción: permiten añadir nuevos registros a la base de datos. Estas consultas utilizan la cláusula INSERT INTO seguida de los valores a insertar.
- Consultas de actualización: permiten modificar los valores de uno o varios registros en la base de datos. Estas consultas utilizan la cláusula UPDATE seguida de los valores a modificar y la cláusula WHERE para especificar los registros a actualizar.
- Consultas de eliminación: permiten eliminar uno o varios registros de la base de datos. Estas consultas utilizan la cláusula DELETE FROM seguida de la cláusula WHERE para especificar los registros a eliminar.
Estos son solo algunos ejemplos de las consultas que se pueden realizar utilizando JPA en un proyecto que combine Apache Mahout y MySQL. La versatilidad de JPA permite adaptarse a las necesidades específicas del proyecto y utilizar diferentes estrategias de mapeo objeto-relacional para obtener la información deseada.
Es posible utilizar Apache Mahout y MySQL sin utilizar JPA? ¿Cuáles serían las implicaciones
Sí, es posible utilizar Apache Mahout y MySQL sin utilizar JPA. Sin embargo, esto implicaría que tendrías que escribir y mantener tu propia lógica de conexión y consultas a la base de datos. Esto puede resultar en un código más complicado y propenso a errores.
JPA (Java Persistence API) es una especificación de Java que proporciona una forma estándar de mapear objetos Java a tablas de base de datos y viceversa. Al utilizar JPA, puedes aprovechar la funcionalidad de ORM (Object-Relational Mapping) que simplifica la interacción con la base de datos y te permite escribir consultas en un lenguaje orientado a objetos en lugar de SQL.
Al utilizar JPA con Apache Mahout y MySQL, puedes aprovechar las capacidades de Mahout para el análisis y la minería de datos, mientras que JPA se encarga de la persistencia de los datos en la base de datos. Esto facilita la integración y te permite aprovechar las características de ambas tecnologías de manera más eficiente.
Por lo tanto, aunque es posible utilizar Apache Mahout y MySQL sin utilizar JPA, utilizar JPA puede simplificar y mejorar tu código al proporcionar una capa de persistencia más sofisticada y fácil de usar.
Existen librerías o frameworks adicionales que se puedan utilizar en conjunto con Apache Mahout, MySQL y JPA para mejorar la experiencia de desarrollo
Si estás trabajando con Apache Mahout, MySQL y JPA, es posible que te preguntes si existen librerías o frameworks adicionales que puedas utilizar para mejorar tu experiencia de desarrollo. La buena noticia es que sí los hay.
Una opción popular es utilizar Hibernate en conjunto con JPA. Hibernate es una implementación ORM (Object-Relational Mapping) que te permite mapear objetos Java a tablas en tu base de datos MySQL. Esto simplifica el proceso de persistencia de datos y te brinda una capa de abstracción adicional.
Integrando Hibernate con JPA y MySQL
Para utilizar Hibernate con JPA en tu proyecto, necesitarás añadir algunas dependencias a tu archivo de configuración. Asegúrate de tener las dependencias correctas para Hibernate y JPA en tu archivo pom.xml si estás utilizando Maven como gestor de dependencias.
Una vez que hayas añadido las dependencias necesarias, deberás configurar tu archivo persistence.xml para establecer la conexión con tu base de datos MySQL. Aquí es donde ingresarás la información de tu URL de conexión, nombre de usuario y contraseña.
Una vez configurado, puedes empezar a utilizar Hibernate con JPA en tu proyecto. Puedes crear entidades JPA y utilizar las anotaciones proporcionadas por Hibernate para especificar el mapeo entre tus objetos y las tablas en tu base de datos MySQL.
También puedes utilizar las funcionalidades avanzadas de Hibernate, como las consultas HQL (Hibernate Query Language) para realizar consultas más complejas en tu base de datos MySQL. Hibernate se encargará de traducir estas consultas a SQL y ejecutarlas en tu base de datos.
Utilizar Hibernate en conjunto con JPA y MySQL puede mejorar tu experiencia de desarrollo al simplificar el proceso de persistencia de datos y proporcionarte una capa de abstracción adicional. Considera integrar estas tecnologías en tu proyecto si estás buscando una solución más robusta y eficiente.
Qué precauciones de seguridad se deben tener en cuenta al conectar Apache Mahout y MySQL utilizando JPA
Cuando conectamos Apache Mahout y MySQL utilizando JPA, es importante tener en cuenta algunas precauciones de seguridad para garantizar la protección de los datos y evitar posibles vulnerabilidades.
En primer lugar, es esencial asegurarse de que la conexión entre Mahout y MySQL esté protegida mediante el uso de protocolos de seguridad adecuados, como SSL. Esto garantizará que la comunicación entre ambos sea cifrada y que los datos no puedan ser interceptados por terceros.
Además, es fundamental implementar mecanismos de autenticación fuertes para acceder a la base de datos. Esto implica utilizar contraseñas seguras y cambiarlas periódicamente, así como también configurar políticas de acceso basadas en roles y privilegios para restringir el acceso a información sensible.
Otro aspecto importante es mantener actualizadas tanto la versión de Mahout como la de MySQL. Las actualizaciones suelen incluir mejoras de seguridad y correcciones de vulnerabilidades conocidas, por lo que es fundamental mantener el software actualizado para evitar posibles brechas de seguridad.
Adicionalmente, se recomienda implementar mecanismos de detección y prevención de intrusiones, como firewalls y sistemas de monitoreo de seguridad. Estas herramientas permitirán identificar y bloquear posibles ataques antes de que puedan comprometer la integridad de los datos.
Por último, es importante tener en cuenta las prácticas de codificación segura al desarrollar aplicaciones que utilicen Mahout y MySQL. Esto implica validar y sanitizar los datos de entrada para prevenir inyecciones de código SQL y otros ataques comunes.
Preguntas frecuentes (FAQ)
¿Qué es Apache Mahout?
Apache Mahout es una biblioteca de aprendizaje automático (machine learning) de código abierto que se utiliza para crear aplicaciones de aprendizaje automático escalables y personalizadas.
¿Qué es MySQL?
MySQL es un sistema de gestión de bases de datos relacional de código abierto que se utiliza para almacenar y administrar datos de manera eficiente.
¿Qué es JPA?
JPA (Java Persistence API) es una interfaz de programación de aplicaciones de Java que permite a los desarrolladores acceder, gestionar y manipular datos en una base de datos relacional utilizando el lenguaje de programación Java.
¿Por qué debería conectar Apache Mahout y MySQL con JPA?
Al conectar Apache Mahout y MySQL con JPA, se puede aprovechar la potencia del aprendizaje automático de Mahout para realizar análisis de datos en la base de datos MySQL y tomar decisiones basadas en esos análisis, todo esto utilizando la facilidad y familiaridad de JPA para acceder a los datos.
¿Es difícil conectar Apache Mahout y MySQL con JPA?
No, conectar Apache Mahout y MySQL con JPA es bastante sencillo. Solo se requiere configurar la conexión a la base de datos en el archivo de configuración de JPA y luego utilizar las clases y métodos proporcionados por Mahout y JPA para acceder y manipular los datos.
Deja una respuesta
Entradas relacionadas