Cómo leer datos con Mahout: la guía definitiva para principiantes
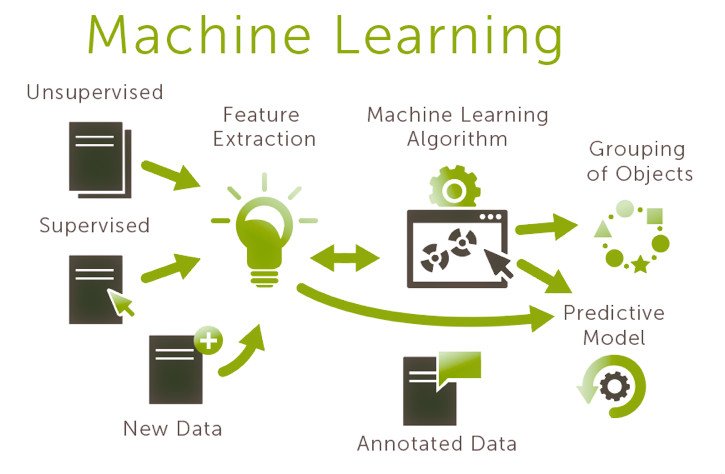
Mahout es una biblioteca de aprendizaje automático de código abierto que está diseñada para ayudar a los desarrolladores a analizar y procesar grandes volúmenes de datos. Con Mahout, los usuarios pueden aplicar algoritmos de aprendizaje automático a sus conjuntos de datos para extraer información valiosa y tomar decisiones más inteligentes. Una de las tareas más comunes que se realiza con Mahout es la lectura y el procesamiento de datos de entrada, que es fundamental para cualquier proyecto de aprendizaje automático.
Exploraremos los conceptos básicos de cómo leer datos utilizando Mahout. Veremos cómo preparar los datos de entrada, qué formatos de archivo son compatibles y cómo cargar y procesar los datos utilizando la biblioteca Mahout. También discutiremos algunas mejores prácticas y consejos para trabajar con datos en Mahout, así como algunos ejemplos de código para ayudarte a comenzar con tu propio proyecto de aprendizaje automático.
- Qué es Mahout y por qué es importante para el análisis de datos
- Cuáles son los pasos básicos para leer datos con Mahout
- Qué formatos de archivo son compatibles con Mahout
- Cuál es la mejor manera de preparar los datos antes de leerlos con Mahout
- Cuáles son las herramientas y algoritmos más utilizados en Mahout para leer datos
- Cuáles son los desafíos comunes al leer datos con Mahout y cómo superarlos
- Existen ejemplos de casos de uso reales donde Mahout ha sido utilizado para leer datos
- Qué alternativas existen a Mahout para leer datos y cómo se comparan
- Cuáles son los recursos y tutoriales disponibles en línea para aprender más sobre cómo leer datos con Mahout
- Qué consejos y trucos recomendarías a los principiantes que están aprendiendo a leer datos con Mahout
- Preguntas frecuentes (FAQ)
Qué es Mahout y por qué es importante para el análisis de datos
Mahout es una biblioteca de aprendizaje automático de código abierto que se utiliza para el análisis de datos. Se ha convertido en una herramienta fundamental para los profesionales que trabajan con grandes conjuntos de datos, ya que permite realizar tareas como la clasificación, la agrupación y la recomendación de datos de manera eficiente.
Gracias a su capacidad para procesar grandes volúmenes de datos de forma rápida y eficiente, Mahout se ha convertido en una herramienta esencial para empresas de diversos sectores, incluyendo el comercio electrónico, la banca y la publicidad en línea. Su popularidad se debe en gran medida a su capacidad para realizar análisis de datos complejos y generar información valiosa para la toma de decisiones empresariales.
Principales características y funcionalidades de Mahout
Mahout ofrece una amplia gama de características y funcionalidades que lo hacen una herramienta poderosa para el análisis de datos. Algunas de las principales características incluyen:
- Algoritmos de aprendizaje automático: Mahout incluye una variedad de algoritmos de aprendizaje automático, como el algoritmo de clasificación bayesiano, el algoritmo de agrupamiento k-means y el algoritmo de recomendación colaborativa.
- Escala en horizontal: Mahout está diseñado para funcionar en entornos distribuidos, lo que significa que puede procesar grandes volúmenes de datos en paralelo utilizando múltiples nodos.
- Integración con Hadoop: Mahout se integra perfectamente con Hadoop, lo que permite aprovechar el poder de procesamiento distribuido de Hadoop para realizar análisis de datos a gran escala.
- Soporte para múltiples formatos de datos: Mahout puede procesar datos en varios formatos, incluyendo texto, secuencia y vectores, lo que facilita su integración con diferentes tipos de conjuntos de datos.
Estas características hacen que Mahout sea una herramienta versátil y flexible que puede adaptarse a diferentes necesidades y requisitos de análisis de datos.
Cuáles son los pasos básicos para leer datos con Mahout
Leer datos con Mahout puede parecer intimidante para los principiantes, pero con los pasos adecuados, se puede dominar esta habilidad. Aquí te presentamos una guía paso a paso sobre cómo leer datos con Mahout.
Paso 1: Preparar los datos
El primer paso es preparar los datos en un formato adecuado para Mahout. Esto implica limpiar los datos, eliminar valores faltantes y asegurarse de que estén en el formato correcto.
Paso 2: Instalar Mahout
Antes de comenzar a leer datos, debes instalar Mahout en tu sistema. Puedes descargarlo desde el sitio oficial de Mahout y seguir las instrucciones de instalación para tu sistema operativo específico.
Paso 3: Importar los datos
Una vez que los datos estén preparados y Mahout esté instalado, el siguiente paso es importar los datos en Mahout. Puedes hacerlo utilizando las funciones de importación de Mahout o escribiendo scripts personalizados para importar los datos.
Paso 4: Explorar los datos
Una vez que los datos estén importados en Mahout, es importante explorar los datos para comprender su estructura y características. Puedes utilizar las funciones de exploración de Mahout para realizar análisis descriptivos básicos y visualizar los datos.
Paso 5: Aplicar algoritmos de aprendizaje automático
Una vez que comprendas los datos, es el momento de aplicar algoritmos de aprendizaje automático en Mahout. Puedes utilizar los algoritmos predefinidos en Mahout o escribir tus propios algoritmos personalizados.
Paso 6: Evaluar y ajustar los modelos
Después de aplicar los algoritmos de aprendizaje automático, es importante evaluar y ajustar los modelos para obtener resultados precisos. Puedes utilizar las funciones de evaluación de Mahout para medir la precisión de los modelos y ajustar los parámetros según sea necesario.
Paso 7: Interpretar los resultados
Finalmente, es importante interpretar los resultados y comunicar los hallazgos obtenidos. Puedes utilizar las funciones de visualización de Mahout para presentar los resultados de manera clara y comprensible.
Leer datos con Mahout puede ser un proceso desafiante pero gratificante. Siguiendo estos pasos, podrás adquirir una comprensión sólida de cómo leer datos con Mahout y aplicar algoritmos de aprendizaje automático para obtener insights valiosos.
Qué formatos de archivo son compatibles con Mahout
Mahout es una biblioteca de aprendizaje automático distribuido que utiliza Apache Hadoop para procesar grandes volúmenes de datos. Cuando se trata de leer datos con Mahout, es importante entender qué formatos de archivo son compatibles. Mahout puede leer archivos en formato CSV (valores separados por comas) y archivos en formato secuencia, como SequenceFile y SequenceVector. Además, también es compatible con archivos en formato libsvm, que es ampliamente utilizado en el aprendizaje automático. Estos formatos de archivo proporcionan una forma fácil y eficiente de almacenar y leer datos en Mahout.
El formato CSV es ampliamente utilizado en la industria y es fácil de entender. Mahout puede leer archivos CSV con diferentes separadores, como comas, punto y coma o tabulaciones. De esta forma, puedes utilizar tus conjuntos de datos existentes sin tener que hacer grandes cambios en su formato.
Por otro lado, Mahout también puede leer archivos en formato secuencia, como SequenceFile y SequenceVector. Estos formatos son comúnmente utilizados para almacenar grandes cantidades de datos en Hadoop. Mahout proporciona utilidades para leer y escribir datos en estos formatos, lo que facilita su integración con otras herramientas y bibliotecas dentro del ecosistema de Hadoop. Al utilizar estos formatos secuenciales, puedes aprovechar la escalabilidad y la capacidad de procesamiento distribuido de Mahout.
Además de los archivos CSV y secuenciales, Mahout también es compatible con el formato libsvm. El formato libsvm es ampliamente utilizado en el aprendizaje automático y es especialmente útil cuando se trata de problemas de clasificación. Este formato representa los datos en una forma escasa, lo que significa que solo se almacenan los valores distintos de cero. Mahout proporciona utilidades para leer y escribir datos en formato libsvm, lo que lo hace compatible con otras herramientas y bibliotecas que también utilizan este formato.
Cuál es la mejor manera de preparar los datos antes de leerlos con Mahout
Antes de leer los datos con Mahout, es importante prepararlos de la mejor manera posible. Esto implica realizar una limpieza de los datos y asegurarse de que estén en el formato adecuado.
La primera etapa de preparación de datos es la limpieza. Esto implica eliminar cualquier dato redundante, como espacios vacíos o caracteres especiales. También es importante eliminar datos incorrectos o incompletos que puedan afectar la precisión de los resultados.
Una vez que los datos están limpios, es importante asegurarse de que estén en el formato adecuado para Mahout. Esto puede implicar la conversión de los datos a un formato de archivo específico o la estructuración de los datos en un formato tabular.
Además, es esencial realizar una exploración preliminar de los datos para comprender su estructura y características. Esto puede ayudar a identificar cualquier patrón o tendencia en los datos, lo que puede influir en la forma en que se leen y analizan con Mahout.
Antes de leer los datos con Mahout, es crucial limpiarlos, asegurarse de que estén en el formato adecuado y realizar una exploración preliminar para comprender su estructura y características.
Cuáles son las herramientas y algoritmos más utilizados en Mahout para leer datos
Mahout es una herramienta de aprendizaje automático de código abierto que se utiliza ampliamente para leer y analizar datos. Ofrece una amplia gama de algoritmos y herramientas que facilitan la tarea de extraer información valiosa de grandes conjuntos de datos.
Algunas de las herramientas y algoritmos más utilizados en Mahout para leer datos son:
1. Mahout Input Format
Mahout Input Format es una herramienta que permite leer datos de diferentes formatos, como archivos de texto, archivos CSV, archivos JSON, etc. Proporciona una forma sencilla de importar y procesar datos en Mahout, lo que facilita la tarea de lectura de datos.
2. Mahout Vector
Mahout Vector es una estructura de datos utilizada para representar características o atributos de un conjunto de datos. Permite almacenar eficientemente grandes vectores de características y proporciona un conjunto de operaciones y funciones para trabajar con ellos.
3. Mahout Sequence File
Mahout Sequence File es un formato de archivo utilizado para almacenar grandes volúmenes de datos estructurados. Proporciona una forma eficiente de leer y escribir datos en Mahout, y es compatible con muchas de las herramientas y algoritmos de Mahout.
4. Mahout Data Model
Mahout Data Model es una biblioteca que proporciona una interfaz unificada para leer y escribir datos en Mahout. Facilita la tarea de manipulación de datos y ofrece una forma sencilla de acceder a las diferentes herramientas y algoritmos de Mahout.
5. Mahout Recommender
Mahout Recommender es una herramienta utilizada para generar recomendaciones basadas en datos. Permite leer datos de usuarios, ítems y relaciones entre ellos, y utilizar diferentes algoritmos de recomendación para generar recomendaciones personalizadas.
Estas son solo algunas de las herramientas y algoritmos más utilizados en Mahout para leer datos. Mahout ofrece muchas otras herramientas y algoritmos que pueden ser de utilidad en diferentes escenarios, por lo que es recomendable explorar la documentación oficial de Mahout para obtener más información.
Cuáles son los desafíos comunes al leer datos con Mahout y cómo superarlos
Cuando se trabaja con Mahout para leer datos, es común enfrentarse a diversos desafíos. Uno de los desafíos más frecuentes es lidiar con la gran cantidad de datos que Mahout puede procesar. Aunque Mahout es una poderosa herramienta para el análisis de big data, puede ser abrumador procesar grandes volúmenes de datos sin una estrategia adecuada.
Una estrategia efectiva para superar este desafío es dividir los datos en conjuntos más pequeños y luego procesarlos por lotes. Esto permite distribuir la carga de trabajo y evitar posibles cuellos de botella en el sistema. Además, es importante optimizar el rendimiento de Mahout ajustando parámetros como la memoria disponible y el tamaño del bloque de datos.
Otro desafío común al leer datos con Mahout es la calidad y consistencia de los datos. Los datos inconsistentes o de baja calidad pueden afectar negativamente los resultados del análisis y dificultar la interpretación de los patrones. Para superar este desafío, es recomendable realizar una limpieza y normalización de los datos antes de procesarlos con Mahout.
La limpieza de datos implica eliminar valores atípicos, datos duplicados o faltantes, y corregir errores en el formato o la estructura de los datos. La normalización de datos implica escalas y transformaciones para asegurar que los datos estén en un rango adecuado para el análisis. Utilizar técnicas de limpieza y normalización de datos en combinación con Mahout puede mejorar la calidad de los resultados y facilitar la interpretación.
Otro desafío al leer datos con Mahout es la selección adecuada de algoritmos y modelos. Mahout ofrece una amplia gama de algoritmos para el análisis de datos, como clustering, clasificación, regresión y recomendación. Sin embargo, elegir el algoritmo adecuado para un problema específico puede resultar complicado.
Para superar este desafío, es importante comprender las características y los requisitos de los algoritmos disponibles en Mahout. Esto incluye comprender las ventajas y limitaciones de cada algoritmo, así como los supuestos subyacentes y los parámetros clave que afectan su rendimiento.
Además, es recomendable experimentar con diferentes algoritmos y ajustar los parámetros para encontrar la mejor combinación para el problema específico. La selección adecuada de algoritmos y modelos en Mahout puede marcar la diferencia en la precisión y eficiencia de los resultados.
Existen ejemplos de casos de uso reales donde Mahout ha sido utilizado para leer datos
Mahout, una biblioteca de aprendizaje automático en Apache Hadoop, ha demostrado ser una herramienta poderosa para leer y analizar datos en muchos casos de uso reales. Uno de estos casos de uso es el análisis de registros de servidores web para identificar patrones de tráfico y comportamiento de los usuarios. Al utilizar Mahout, las empresas pueden extraer información valiosa de grandes volúmenes de datos web y tomar decisiones basadas en datos.
Otro caso de uso común es el análisis de texto, donde Mahout puede ser utilizado para analizar grandes cantidades de documentos y extraer información relevante, como palabras clave y temas. Esto es especialmente útil en industrias como la publicidad en línea, donde la comprensión del contenido de los anuncios y las páginas de destino es crucial para la segmentación y personalización efectiva.
Además, Mahout puede utilizarse para el análisis de recomendaciones, donde los algoritmos de filtrado colaborativo se utilizan para recomendar productos o contenido relevante a los usuarios. Esto es especialmente útil en comercio electrónico y servicios de transmisión de contenido, donde la personalización y la recomendación precisa pueden mejorar la experiencia del usuario y aumentar las tasas de conversión.
Mahout ha sido utilizado con éxito en varios casos de uso reales, incluyendo análisis de registros de servidores web, análisis de texto y recomendaciones. Al aprovechar las capacidades de aprendizaje automático de Mahout, las empresas pueden tomar decisiones basadas en datos, extraer información valiosa y mejorar la experiencia del usuario.
Qué alternativas existen a Mahout para leer datos y cómo se comparan
Existen varias alternativas a Mahout para leer datos, dependiendo de las necesidades y el entorno de trabajo. Una de las alternativas más populares es Apache Spark, que proporciona una interfaz fácil de usar y ofrece una gran cantidad de funcionalidades para el procesamiento de datos. Otra opción es Hadoop, que es un framework de código abierto diseñado para el procesamiento y almacenamiento distribuido de grandes volúmenes de datos. También está TensorFlow, una biblioteca de software de código abierto utilizada para el aprendizaje automático y la inteligencia artificial.
Al comparar estas alternativas con Mahout, es importante tener en cuenta factores como la facilidad de uso, la escalabilidad, la compatibilidad con diferentes tipos de datos y la disponibilidad de algoritmos y herramientas específicas. Mahout se destaca por su capacidad para trabajar con datos distribuidos y su amplia gama de algoritmos de aprendizaje automático. Sin embargo, otras alternativas como Apache Spark ofrecen una mayor flexibilidad y un ecosistema más completo para el procesamiento y análisis de datos.
Cuáles son los recursos y tutoriales disponibles en línea para aprender más sobre cómo leer datos con Mahout
Si estás interesado en aprender cómo leer datos con Mahout, estás de suerte. Hay una gran cantidad de recursos y tutoriales disponibles en línea que pueden ayudarte a dominar esta habilidad.
En primer lugar, puedes consultar la documentación oficial de Mahout. Allí encontrarás guías detalladas, ejemplos de código y preguntas frecuentes que te ayudarán a comprender los conceptos básicos de la lectura de datos con Mahout.
Además, hay una serie de tutoriales en video disponibles en plataformas como YouTube. Estos videos te mostrarán paso a paso cómo leer datos con Mahout y te brindarán ejemplos prácticos para que puedas poner en práctica tus conocimientos.
Si prefieres aprender a través de la lectura, hay varios libros sobre Mahout disponibles en librerías en línea. Estos libros cubren desde los conceptos básicos hasta técnicas más avanzadas, y muchos de ellos incluyen ejemplos de código que puedes seguir.
Además de los recursos en línea, también puedes considerar unirte a comunidades y foros de Mahout. Allí podrás hacer preguntas, obtener ayuda de otros usuarios y participar en discusiones que te ayudarán a expandir tus conocimientos sobre cómo leer datos con Mahout.
Si estás interesado en aprender cómo leer datos con Mahout, hay una amplia gama de recursos disponibles en línea que pueden ayudarte en tu proceso de aprendizaje. Ya sea a través de la documentación oficial, tutoriales en video, libros o comunidades y foros, tienes todas las herramientas necesarias para convertirte en un experto en la lectura de datos con Mahout.
Qué consejos y trucos recomendarías a los principiantes que están aprendiendo a leer datos con Mahout
Si eres un principiante que está aprendiendo a leer datos con Mahout, aquí tienes algunos consejos y trucos que te serán útiles en tu camino hacia la maestría en esta poderosa herramienta.
1. Familiarízate con la estructura de los datos
Es fundamental comprender la estructura de los datos con los que estás trabajando. Esto incluye el formato del archivo, los campos y su significado, así como la forma en que están organizados. Esto te permitirá leer e interpretar los datos de manera más eficiente.
2. Utiliza las funciones de lectura de Mahout
Mahout ofrece una serie de funciones integradas para leer datos en diferentes formatos, como CSV, texto plano o archivos Hadoop. Aprovecha estas funciones para simplificar el proceso de lectura y garantizar la integridad de los datos.
3. Limpia y preprocesa tus datos
Antes de comenzar el análisis, es importante limpiar y preprocesar tus datos para eliminar cualquier ruido o inconsistencia. Puedes utilizar las herramientas de Mahout para realizar operaciones de limpieza, normalización y transformación de datos.
4. Experimenta con diferentes algoritmos
Mahout ofrece una amplia variedad de algoritmos de aprendizaje automático para analizar tus datos. No te limites a utilizar solo un algoritmo, experimenta con diferentes opciones y compara sus resultados. Esto te ayudará a encontrar la mejor solución para tu problema.
5. Aprovecha la comunidad y los recursos en línea
La comunidad de Mahout es una gran fuente de conocimiento y apoyo. Participa en foros, grupos de discusión y eventos para aprender de otros usuarios y obtener consejos útiles. Además, hay una gran cantidad de tutoriales y documentación en línea disponibles que te ayudarán a profundizar tus conocimientos.
En conclusión
Leer datos con Mahout puede parecer desafiante al principio, pero siguiendo estos consejos y trucos podrás dominar esta herramienta y aprovechar al máximo su potencial. Recuerda siempre practicar y experimentar con tus propios conjuntos de datos para obtener resultados más precisos y relevantes.
Preguntas frecuentes (FAQ)
1. ¿Qué es Mahout y para qué se utiliza?
Mahout es una biblioteca de aprendizaje automático que permite a los desarrolladores implementar algoritmos en grandes conjuntos de datos. Se utiliza para realizar recomendaciones, segmentación de clientes y clustering, entre otras tareas de inteligencia artificial.
2. ¿Es necesario tener conocimientos avanzados de programación para usar Mahout?
No, Mahout está diseñado para ser fácil de usar incluso para principiantes en programación. Sin embargo, es útil tener conocimientos básicos de programación y estadísticas para comprender mejor los algoritmos y los resultados obtenidos.
3. ¿Qué tipos de datos puede leer Mahout?
Mahout puede leer una amplia variedad de tipos de datos, incluyendo archivos de texto, archivos CSV y archivos de vectores densos o dispersos. También puede leer datos almacenados en Hadoop Distributed File System (HDFS) o en Amazon S3.
4. ¿Puedo usar Mahout en mi propio clúster de Hadoop?
Sí, Mahout está diseñado para funcionar en clústeres de Hadoop utilizando el framework de Apache Spark para el procesamiento distribuido. Esto permite aprovechar la escalabilidad y la capacidad de manejo de grandes volúmenes de datos de Hadoop.
5. ¿Hay alguna documentación adicional o recursos de aprendizaje sobre Mahout?
Sí, aparte de la documentación oficial de Mahout, hay varios tutoriales y libros disponibles en línea que pueden ayudarte a aprender más sobre Mahout y cómo utilizarlo en tus proyectos de aprendizaje automático.
Deja una respuesta
Entradas relacionadas