Aprende a dominar Apache Mahout para predecir con precisión
Apache Mahout es una poderosa biblioteca de aprendizaje automático desarrollada por la Fundación Apache. Esta herramienta se utiliza para el análisis de datos y la construcción de modelos predictivos, lo que la convierte en una opción popular entre los profesionales de la ciencia de datos. Si estás interesado en profundizar tus conocimientos en el campo del aprendizaje automático y quieres aprender a utilizar Apache Mahout para predecir con precisión, has llegado al lugar correcto.
Te proporcionaremos una guía completa sobre cómo dominar Apache Mahout y usarlo para realizar predicciones precisas. Te explicaremos los conceptos básicos del aprendizaje automático y cómo funciona Mahout, así como los diferentes algoritmos de aprendizaje automático que puedes utilizar con esta biblioteca. También aprenderás cómo preparar tus datos y cómo evaluar la precisión de tus modelos de predicción. Ya seas un principiante en el aprendizaje automático o tengas experiencia previa, este artículo te ayudará a llevar tus habilidades al siguiente nivel.
- Cuáles son los conceptos básicos de Apache Mahout y por qué son importantes para la predicción precisa
- Qué algoritmos de aprendizaje automático ofrece Apache Mahout y cómo se utilizan para la predicción
- Cuáles son los pasos para implementar un modelo de predicción en Apache Mahout
- Cómo se pueden evaluar y optimizar los modelos de predicción en Apache Mahout
- Cuáles son algunos casos de uso comunes de Apache Mahout en la predicción precisa
- Cómo se puede combinar Apache Mahout con otras herramientas y tecnologías para mejorar la precisión de la predicción
- Cuáles son los desafíos comunes al utilizar Apache Mahout para la predicción y cómo superarlos
- Existen recursos de aprendizaje en línea para dominar Apache Mahout y mejorar las habilidades de predicción
- Cuáles son las últimas actualizaciones y novedades en Apache Mahout que los desarrolladores y analistas deben conocer
-
Preguntas frecuentes (FAQ)
- 1. ¿Qué es Apache Mahout?
- 2. ¿Cuáles son los casos de uso comunes para Apache Mahout?
- 3. ¿Es necesario ser un experto en programación para utilizar Apache Mahout?
- 4. ¿Qué lenguajes de programación son compatibles con Apache Mahout?
- 5. ¿Cuáles son las ventajas de utilizar Apache Mahout en comparación con otras bibliotecas de aprendizaje automático?
Cuáles son los conceptos básicos de Apache Mahout y por qué son importantes para la predicción precisa
Apache Mahout es una biblioteca de aprendizaje automático de código abierto que se utiliza para construir algoritmos y modelos de aprendizaje automático. Es extremadamente popular en la industria debido a su capacidad para procesar grandes volúmenes de datos y proporcionar predicciones precisas.
Para comprender completamente Apache Mahout y aprovechar su potencial, es importante tener una comprensión sólida de los conceptos básicos. Uno de estos conceptos es el uso de algoritmos de agrupamiento. Los algoritmos de agrupamiento permiten agrupar datos similares en clústeres, lo que es esencial para la predicción precisa.
Otro concepto clave es la regresión lineal. La regresión lineal es un método estadístico utilizado para predecir el valor de una variable dependiente en función de una o más variables independientes. Es especialmente útil para predecir valores numéricos, como ventas o precios.
Por último, pero no menos importante, es importante comprender los algoritmos de clasificación. Los algoritmos de clasificación se utilizan para predecir en qué categoría o clase se clasificará una instancia determinada. Esto puede ser útil para la clasificación de textos, detección de spam, entre otros muchos casos.
Los conceptos básicos de Apache Mahout, como los algoritmos de agrupamiento, regresión lineal y clasificación, son fundamentales para lograr una predicción precisa. Dominar estos conceptos permitirá a los profesionales del aprendizaje automático aprovechar al máximo esta poderosa biblioteca y generar resultados confiables y precisos.
Qué algoritmos de aprendizaje automático ofrece Apache Mahout y cómo se utilizan para la predicción
Apache Mahout es una poderosa biblioteca de aprendizaje automático que ofrece una amplia gama de algoritmos para la predicción. Algunos de los algoritmos más populares incluyen el filtrado colaborativo, el agrupamiento y las reglas de asociación.
El filtrado colaborativo es ampliamente utilizado en sistemas de recomendación. Mahout ofrece implementaciones de algoritmos como User-Based Collaborative Filtering y Item-Based Collaborative Filtering, que permiten predecir las preferencias de un usuario en función de las calificaciones de otros usuarios o artículos similares.
El agrupamiento, también conocido como clustering, es útil para identificar patrones y grupos en conjuntos de datos. Mahout ofrece algoritmos de agrupamiento como K-means y Mean Shift, que permiten agrupar datos de manera eficiente y automatizada.
Las reglas de asociación son algoritmos que permiten encontrar relaciones interesantes entre diferentes elementos en conjuntos de datos. Mahout proporciona algoritmos como Apriori y FP-Growth, que permiten encontrar patrones frecuentes y reglas de asociación entre diversos elementos en un conjunto de datos.
Estos son solo algunos ejemplos de los algoritmos de aprendizaje automático que Apache Mahout ofrece para la predicción. Cada algoritmo tiene su propio conjunto de parámetros y se puede adaptar a diferentes escenarios y conjuntos de datos para lograr una mayor precisión en las predicciones.
Cuáles son los pasos para implementar un modelo de predicción en Apache Mahout
Implementar un modelo de predicción en Apache Mahout puede parecer complicado, pero con los pasos correctos, es posible lograrlo con precisión. A continuación, te mostraré los pasos necesarios para ayudarte a dominar esta poderosa herramienta.
Paso 1: Instalación de Apache Mahout
Lo primero que debes hacer es instalar Apache Mahout en tu sistema. Puedes descargar el paquete de instalación desde el sitio oficial de Mahout y seguir las instrucciones de instalación proporcionadas. Asegúrate de tener todas las dependencias necesarias para que Mahout funcione correctamente en tu entorno.
Paso 2: Preparación de datos
Antes de comenzar a construir modelos de predicción, es fundamental contar con los datos adecuados. Asegúrate de tener un conjunto de datos bien estructurado y limpio para obtener resultados precisos. Mahout admite varios formatos de datos, como CSV, texto plano o archivos de secuencia. Asegúrate de transformar tus datos en el formato aceptado por Mahout.
Paso 3: Selección del algoritmo de predicción
Mahout ofrece una amplia gama de algoritmos de predicción, como filtrado colaborativo, clustering, recomendación, entre otros. Debes seleccionar el algoritmo adecuado según tus necesidades y los tipos de datos que tengas. Investiga y analiza los diferentes algoritmos disponibles en Mahout y elige el más adecuado para tu caso de uso.
Paso 4: Construcción del modelo de predicción
Una vez que hayas seleccionado el algoritmo de predicción, es hora de construir el modelo. Utiliza la API de Mahout para crear un modelo basado en tus datos de entrenamiento. Asegúrate de ajustar los parámetros del modelo según tus necesidades y realiza varios experimentos para encontrar el mejor modelo posible.
Paso 5: Evaluación del modelo
No te olvides de evaluar la precisión de tu modelo de predicción. Utiliza técnicas de validación cruzada para medir el rendimiento del modelo en datos no vistos. Mahout proporciona herramientas y métricas para evaluar tus modelos, como el error cuadrático medio o la precisión y exhaustividad.
Paso 6: Implementación y despliegue del modelo
Una vez que hayas construido y evaluado tu modelo de predicción, llega el momento de implementarlo en tu entorno de producción. Utiliza la API de Mahout para cargar y utilizar el modelo en tu aplicación. Asegúrate de realizar pruebas exhaustivas y monitorear el rendimiento del modelo en producción.
Paso 7: Mejora continua y ajuste del modelo
El proceso de construir modelos de predicción es iterativo y continuo. A medida que recopiles más datos y obtengas resultados reales, es posible que necesites ajustar y mejorar tu modelo. Utiliza técnicas de retroalimentación y aprendizaje continuo para mejorar la precisión de tu modelo de predicción en el tiempo.
Con estos pasos, estarás en el camino correcto para dominar Apache Mahout y utilizarlo eficazmente para predecir con precisión. Recuerda que la práctica constante y la exploración de diferentes técnicas te ayudarán a convertirte en un experto en Mahout.
Cómo se pueden evaluar y optimizar los modelos de predicción en Apache Mahout
Apache Mahout es una poderosa biblioteca de aprendizaje automático que ofrece una amplia gama de algoritmos y herramientas para crear modelos de predicción. Sin embargo, construir un modelo preciso no es suficiente, también es fundamental evaluar y optimizar su rendimiento. En este artículo, aprenderemos cómo evaluar y optimizar los modelos de predicción en Apache Mahout.
Evaluación de modelos de predicción
La evaluación de un modelo de predicción es crucial para comprender su rendimiento y determinar si es adecuado para su uso en aplicaciones del mundo real. En Apache Mahout, podemos utilizar varias técnicas de evaluación, como la validación cruzada, la matriz de confusión y las métricas de rendimiento como la precisión, el recuerdo y la F1-score.
La validación cruzada es una técnica común utilizada para evaluar modelos de predicción. Nos permite dividir nuestro conjunto de datos en múltiples subconjuntos de entrenamiento y prueba, y evaluar el rendimiento del modelo en cada subconjunto. Esto nos brinda una visión general del rendimiento del modelo y nos ayuda a identificar posibles problemas, como sobreajuste o subajuste.
Otra técnica útil es la matriz de confusión, que nos muestra la cantidad de predicciones correctas e incorrectas que hace nuestro modelo en cada clase. Esto nos permite identificar qué clases se confunden con más frecuencia y nos ayuda a comprender mejor el rendimiento del modelo en diferentes escenarios.
Cuáles son algunos casos de uso comunes de Apache Mahout en la predicción precisa
Apache Mahout es una biblioteca de aprendizaje automático distribuida que se utiliza para construir sistemas de recomendación, filtrado colaborativo, clasificación y regresión. Ofrece una amplia gama de algoritmos de aprendizaje automático, como k-means, descenso de gradiente estocástico y árboles de decisión.
Uno de los casos de uso más comunes de Apache Mahout es en sistemas de recomendación, donde se utiliza para predecir y sugerir productos o contenido relevante a los usuarios. Esto se logra mediante algoritmos de filtrado colaborativo que analizan el comportamiento y las preferencias de los usuarios para hacer recomendaciones personalizadas.
Otro caso de uso común es en la clasificación de datos, donde Mahout puede ser utilizado para predecir la clase o categoría a la que pertenece un nuevo conjunto de datos. Esto es particularmente útil en aplicaciones de detección de spam, análisis de sentimientos y clasificación de noticias.
Además, Apache Mahout también se puede utilizar para la predicción de series de tiempo, donde se analizan y predicen patrones y tendencias a partir de datos secuenciales. Esto es especialmente útil en aplicaciones financieras, como la predicción de precios de acciones o el pronóstico de ventas.
Apache Mahout es una herramienta poderosa para la predicción precisa en una variedad de casos de uso, desde sistemas de recomendación hasta clasificación y pronóstico de series de tiempo. Con su conjunto de algoritmos de aprendizaje automático y su capacidad para manejar grandes volúmenes de datos, Mahout es una opción popular para aquellos que buscan implementar soluciones de análisis predictivo.
Cómo se puede combinar Apache Mahout con otras herramientas y tecnologías para mejorar la precisión de la predicción
Cuando se trata de mejorar la precisión de la predicción utilizando Apache Mahout, hay varias herramientas y tecnologías que se pueden combinar para lograr resultados aún más precisos. Una de las formas más comunes de hacerlo es aprovechar el poder del aprendizaje automático en combinación con Mahout.
El aprendizaje automático es una disciplina que se centra en el desarrollo de algoritmos que permiten a las computadoras aprender y mejorar de forma autónoma a partir de los datos. Al combinar Mahout con el aprendizaje automático, es posible mejorar la precisión de la predicción al permitir que el sistema identifique automáticamente patrones y tendencias en los datos.
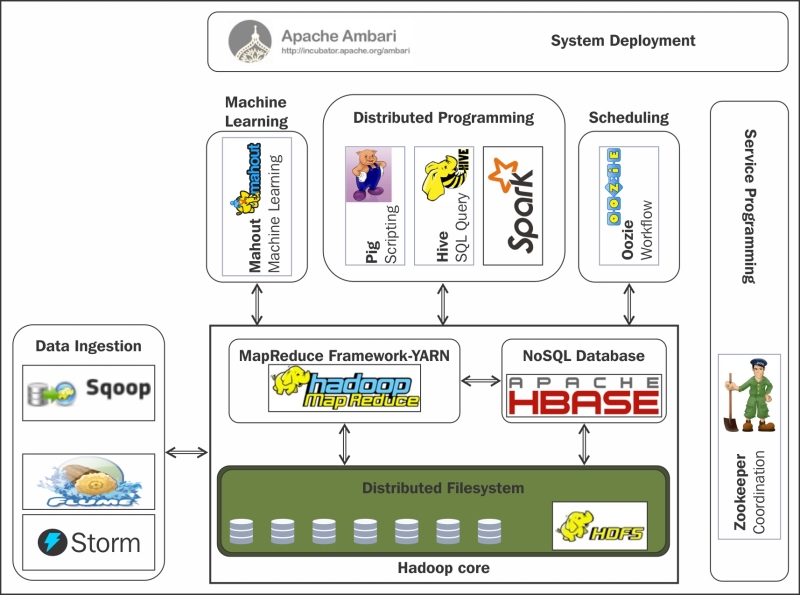
Otra forma de combinar Mahout con otras herramientas y tecnologías es utilizar plataformas de big data, como Apache Hadoop. Hadoop es un marco de trabajo que permite procesar grandes volúmenes de datos de manera distribuida y escalable. Al utilizar Mahout junto con Hadoop, es posible aprovechar la capacidad de procesamiento distribuido para mejorar la velocidad y precisión de la predicción.
También es posible combinar Mahout con otras bibliotecas y lenguajes de programación, como Python y TensorFlow. Estas bibliotecas y lenguajes son ampliamente utilizados en el campo del aprendizaje automático y ofrecen una amplia gama de algoritmos y técnicas avanzadas que pueden mejorar la precisión de la predicción.
Por último, otra forma de combinar Mahout con otras herramientas y tecnologías es utilizar técnicas de preprocesamiento de datos avanzadas. Estas técnicas incluyen la limpieza de datos, la eliminación de valores atípicos y la normalización de datos. Al utilizar técnicas de preprocesamiento de datos junto con Mahout, es posible mejorar la calidad de los datos de entrada y, en última instancia, mejorar la precisión de la predicción.
Cuáles son los desafíos comunes al utilizar Apache Mahout para la predicción y cómo superarlos
Al utilizar Apache Mahout para la predicción, es común encontrarse con varios desafíos que pueden dificultar el proceso. Uno de los principales desafíos es la falta de conocimiento en el uso de algoritmos de aprendizaje automático y minería de datos.
Para superar este desafío, es fundamental adquirir conocimientos sólidos sobre los diferentes algoritmos y su aplicación en Apache Mahout. Esto se puede lograr mediante la lectura de documentación y tutoriales, así como mediante la participación en cursos o programas de formación en aprendizaje automático.
Otro desafío común es la falta de datos de calidad para alimentar los algoritmos de predicción. Los algoritmos de aprendizaje automático requieren de datos precisos y representativos para generar modelos precisos.
Para superar este desafío, se recomienda realizar una exploración exhaustiva de los datos disponibles y, si es necesario, recopilar más datos o mejorar la calidad de los existentes. También es importante prestar atención a la limpieza y normalización de los datos, para garantizar su validez y consistencia.
Por último, otro desafío común al utilizar Apache Mahout para la predicción es la optimización de los modelos generados. Los algoritmos de aprendizaje automático pueden generar modelos complejos que requieren una optimización cuidadosa para mejorar su precisión y rendimiento.
Para superar este desafío, se pueden utilizar técnicas de ajuste de hiperparámetros, como la validación cruzada y la búsqueda en cuadrícula, para encontrar la configuración óptima de los modelos. También es importante realizar evaluaciones periódicas de los modelos para identificar posibles mejoras y ajustes.
Al utilizar Apache Mahout para la predicción, es importante enfrentar y superar los desafíos comunes que pueden surgir en el proceso. Adquirir conocimientos en algoritmos de aprendizaje automático, asegurarse de tener datos de calidad y optimizar los modelos generados son aspectos clave para lograr predicciones precisas.
Existen recursos de aprendizaje en línea para dominar Apache Mahout y mejorar las habilidades de predicción
Apache Mahout es una excelente herramienta de aprendizaje automático que permite a los desarrolladores crear modelos predictivos precisos. Sin embargo, para dominar completamente Mahout y obtener resultados precisos, es necesario contar con recursos de aprendizaje en línea que proporcionen una guía detallada sobre su uso y aplicaciones. Afortunadamente, existen numerosos recursos en línea, como cursos, tutoriales y documentación oficial, que pueden ayudarte a mejorar tus habilidades de predicción con Mahout.
Uno de los recursos más populares para aprender Apache Mahout es el curso en línea ofrecido por plataformas de educación virtual. Estos cursos están diseñados para enseñar a los estudiantes cómo utilizar Mahout de manera efectiva para crear modelos predictivos precisos. Los cursos generalmente cubren temas como la instalación y configuración de Mahout, la construcción de modelos predictivos y la evaluación de su rendimiento. A través de ejercicios prácticos y casos de uso reales, los estudiantes pueden adquirir experiencia práctica en el uso de Mahout.
Además de los cursos en línea, existen tutoriales gratuitos disponibles en blogs y sitios web especializados. Estos tutoriales proporcionan un enfoque paso a paso sobre cómo utilizar Mahout para predecir con precisión en diferentes escenarios. Los tutoriales generalmente incluyen ejemplos de código y explicaciones detalladas para facilitar la comprensión de los conceptos clave de Mahout. Al seguir estos tutoriales, los desarrolladores pueden adquirir habilidades prácticas y comprender cómo aplicar Mahout en su propio entorno de desarrollo.
La documentación oficial de Apache Mahout también es una excelente fuente de información para dominar la herramienta
La documentación oficial de Apache Mahout es otra fuente invaluable de información para aquellos que deseen dominar la herramienta. Esta documentación detallada proporciona una descripción exhaustiva de todas las características y funcionalidades de Mahout, junto con ejemplos de código y casos de uso. La documentación también incluye guías de instalación, configuración y solución de problemas, lo que la convierte en un recurso completo y confiable para cualquier desarrollador que trabaje con Mahout.
Además de los cursos, tutoriales y documentación oficial, también puedes participar en comunidades en línea y foros de discusión dedicados a Mahout. Estas comunidades son excelentes lugares para interactuar con otros desarrolladores y expertos en Mahout, compartir conocimientos, hacer preguntas y obtener orientación sobre cómo mejorar tus habilidades de predicción con Mahout. A través de la participación activa en estas comunidades, puedes obtener ideas valiosas y encontrar soluciones a problemas desafiantes que pueden surgir durante tu trabajo con Mahout.
Dominar Apache Mahout para predecir con precisión es posible gracias a los diversos recursos de aprendizaje en línea disponibles. Ya sea a través de cursos en línea, tutoriales gratuitos, documentación oficial o comunidades en línea, tienes la oportunidad de mejorar tus habilidades y adquirir experiencia práctica en el uso de Mahout. No dudes en explorar estos recursos y aprovechar al máximo tu potencial en el campo del aprendizaje automático con Mahout.
Cuáles son las últimas actualizaciones y novedades en Apache Mahout que los desarrolladores y analistas deben conocer
Apache Mahout es una biblioteca de aprendizaje automático de código abierto que ha experimentado varias actualizaciones y mejoras en los últimos tiempos. Estas nuevas características hacen que sea más fácil y eficiente para los desarrolladores y analistas trabajar con Apache Mahout y predecir con mayor precisión.
Una de las últimas actualizaciones en Apache Mahout es la inclusión de algoritmos de aprendizaje profundo, lo que permite a los usuarios realizar tareas más complejas y obtener resultados más precisos. Esto es especialmente útil en aplicaciones de procesamiento de imágenes y reconocimiento de voz.
Otra novedad importante en Apache Mahout es la capacidad de trabajar con grandes volúmenes de datos en sistemas distribuidos. Esto permite a los desarrolladores escalar sus aplicaciones y manejar conjuntos de datos masivos de manera eficiente, lo que es esencial en entornos de big data.
Además, se han agregado nuevas funcionalidades a los algoritmos de clasificación y agrupación en Apache Mahout. Ahora es posible utilizar algoritmos más avanzados y personalizar los modelos de aprendizaje automático según las necesidades específicas de cada proyecto.
También se ha mejorado la integración de Apache Mahout con otras bibliotecas y frameworks populares, como Apache Spark y Hadoop. Esto permite a los usuarios aprovechar las capacidades de procesamiento distribuido de estas plataformas y mejorar aún más el rendimiento y la escalabilidad de sus aplicaciones.
Las últimas actualizaciones y novedades en Apache Mahout han hecho que sea más fácil y poderoso para los desarrolladores y analistas trabajar con esta biblioteca de aprendizaje automático. Con la inclusión de algoritmos de aprendizaje profundo, el manejo de grandes volúmenes de datos y las mejoras en los algoritmos de clasificación y agrupación, Apache Mahout se posiciona como una herramienta clave para predecir con precisión en el campo del análisis de datos.
Preguntas frecuentes (FAQ)
1. ¿Qué es Apache Mahout?
Apache Mahout es una biblioteca de aprendizaje automático distribuido y de código abierto que se utiliza para construir aplicaciones de análisis predictivo y recomendaciones inteligentes.
2. ¿Cuáles son los casos de uso comunes para Apache Mahout?
Algunos casos de uso comunes para Apache Mahout incluyen filtrado colaborativo, clustering, clasificación y recomendaciones personalizadas.
3. ¿Es necesario ser un experto en programación para utilizar Apache Mahout?
No, aunque se requiere conocimiento básico de programación, Apache Mahout proporciona una interfaz fácil de usar y documentación detallada para ayudar a los principiantes a empezar.
4. ¿Qué lenguajes de programación son compatibles con Apache Mahout?
Apache Mahout es compatible principalmente con Java, pero también ofrece soporte para Scala y R.
5. ¿Cuáles son las ventajas de utilizar Apache Mahout en comparación con otras bibliotecas de aprendizaje automático?
Algunas de las ventajas de utilizar Apache Mahout son su capacidad de procesamiento distribuido, su enfoque en algoritmos de aprendizaje supervisado y no supervisado, y su integración con otras herramientas de Big Data como Apache Hadoop y Apache Spark.
Deja una respuesta
Entradas relacionadas