Apache Mahout: cómo estimar las preferencias de tus usuarios
En el mundo actual, donde la cantidad de datos generados por los usuarios es cada vez mayor, es de vital importancia para las empresas poder analizar y comprender el comportamiento de los usuarios para ofrecerles una experiencia personalizada. Una de las formas de lograr esto es a través de la estimación de las preferencias de los usuarios, es decir, predecir qué productos o contenidos pueden resultar de su agrado. Es aquí donde Apache Mahout se convierte en una herramienta fundamental.
Exploraremos en detalle qué es Apache Mahout y cómo puede ayudarte a estimar las preferencias de tus usuarios. Hablaremos sobre los algoritmos de recomendación que utiliza Mahout y cómo puedes implementarlos en tu propio sistema. Además, te mostraremos ejemplos prácticos de cómo Mahout ha sido utilizado por diferentes empresas para mejorar la experiencia de sus usuarios. Si estás interesado en comprender más sobre cómo utilizar Big Data para personalizar tus servicios, ¡continúa leyendo!
- Qué es Apache Mahout y cómo se utiliza para estimar las preferencias de los usuarios
- Cuál es la importancia de estimar las preferencias de los usuarios en un negocio en línea
- Cuáles son los algoritmos y técnicas utilizados por Apache Mahout para realizar la estimación de preferencias
- Cómo se puede aplicar Apache Mahout en diferentes industrias y sectores
- Cuáles son los beneficios de utilizar Apache Mahout para la estimación de preferencias de los usuarios
- Cuáles son algunos ejemplos de aplicaciones exitosas de Apache Mahout en la estimación de preferencias de los usuarios
- Cuáles son los desafíos y limitaciones de utilizar Apache Mahout para la estimación de preferencias de los usuarios
- Existen alternativas a Apache Mahout para la estimación de preferencias de los usuarios
- Cuáles son algunas buenas prácticas para implementar Apache Mahout de manera efectiva en la estimación de preferencias de los usuarios
- Cuáles son las últimas tendencias y avances en el campo de la estimación de preferencias de los usuarios utilizando Apache Mahout
- Preguntas frecuentes (FAQ)
Qué es Apache Mahout y cómo se utiliza para estimar las preferencias de los usuarios
Apache Mahout es una biblioteca de aprendizaje automático distribuido y de código abierto que se utiliza para el análisis de datos y la minería de datos. Permite a los desarrolladores implementar algoritmos de aprendizaje automático en sistemas distribuidos y de alto rendimiento.
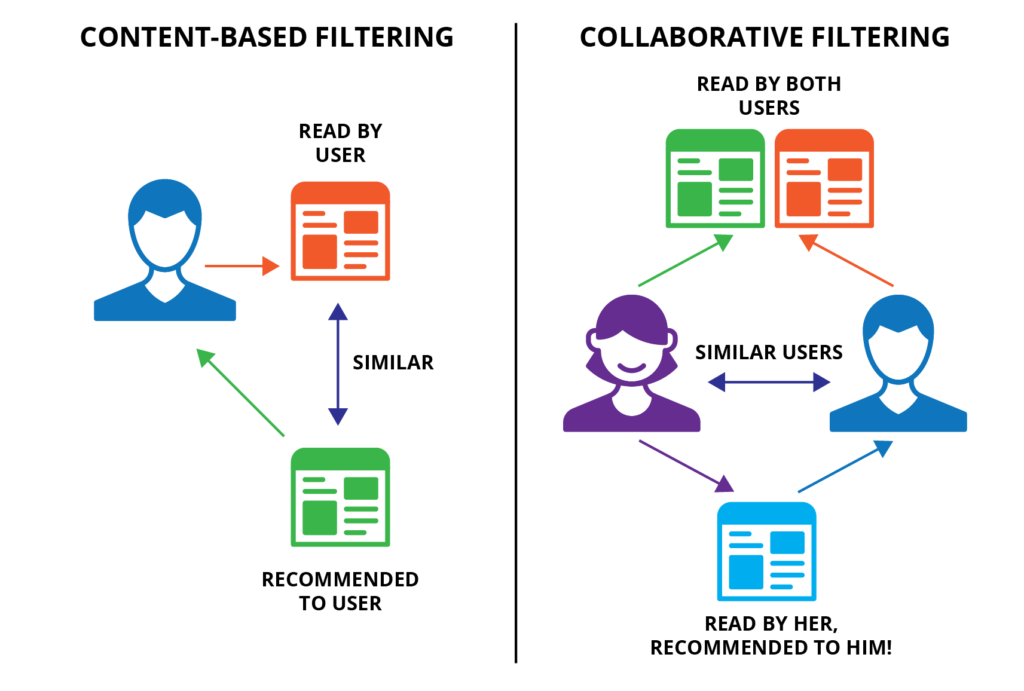
Con Apache Mahout, puedes estimar las preferencias de tus usuarios utilizando técnicas de filtrado colaborativo, que se basan en el comportamiento de los usuarios similares. Esto te permite ofrecer recomendaciones personalizadas a tus usuarios.
Para utilizar Apache Mahout, necesitarás tener conocimientos de programación en Java, ya que es una biblioteca escrita en Java. También necesitarás un conjunto de datos de usuarios y sus preferencias para entrenar el modelo de aprendizaje automático.
Cómo funciona Apache Mahout
Apache Mahout utiliza algoritmos de filtrado colaborativo para estimar las preferencias de los usuarios. Estos algoritmos analizan el comportamiento de los usuarios similares y utilizan esa información para hacer recomendaciones personalizadas.
El proceso de estimación de preferencias con Apache Mahout consta de varias etapas:
- Preprocesamiento de datos: en esta etapa, los datos de usuarios y preferencias se preparan para el análisis. Esto puede incluir la eliminación de datos incorrectos o incompletos, la normalización de los datos y la representación en una estructura adecuada.
- Selección de algoritmo: en esta etapa, se selecciona el algoritmo de filtrado colaborativo adecuado para el análisis de tus datos. Apache Mahout ofrece varios algoritmos populares, como User-based Collaborative Filtering, Item-based Collaborative Filtering y Matrix Factorization.
- Entrenamiento del modelo: en esta etapa, se utiliza el conjunto de datos de usuarios y preferencias para entrenar el modelo de aprendizaje automático. El modelo aprenderá los patrones y relaciones entre los usuarios y sus preferencias.
- Estimación de preferencias: una vez que el modelo ha sido entrenado, se puede utilizar para estimar las preferencias de los usuarios. El modelo analiza el comportamiento de los usuarios similares y utiliza esa información para hacer recomendaciones personalizadas.
Apache Mahout es una biblioteca de aprendizaje automático distribuido que se utiliza para estimar las preferencias de los usuarios utilizando técnicas de filtrado colaborativo. Con Apache Mahout, puedes ofrecer recomendaciones personalizadas a tus usuarios basadas en el comportamiento de los usuarios similares.
Cuál es la importancia de estimar las preferencias de los usuarios en un negocio en línea
La estimación de las preferencias de los usuarios en un negocio en línea es crucial para ofrecer una experiencia personalizada y relevante. Al comprender los gustos y necesidades de los clientes, las empresas pueden adaptar sus productos, recomendaciones y estrategias de marketing para maximizar la satisfacción y fidelidad del usuario. Además, las estimaciones de preferencias permiten identificar patrones y tendencias en el comportamiento del consumidor, lo que puede ayudar a predecir y anticipar las necesidades futuras. La estimación de preferencias es una herramienta invaluable para mejorar la toma de decisiones y optimizar los resultados en línea.
Cuáles son los algoritmos y técnicas utilizados por Apache Mahout para realizar la estimación de preferencias
Apache Mahout utiliza una variedad de algoritmos y técnicas para estimar las preferencias de los usuarios. Entre los más comunes, se encuentran:
1. Filtrado colaborativo
El filtrado colaborativo es una técnica que se basa en la idea de que si a una persona le gusta un conjunto de artículos y a otra persona también le gusta ese mismo conjunto, entonces es probable que también le gusten otros artículos en común. Apache Mahout implementa algoritmos como User-based y Item-based Collaborative Filtering para realizar esta estimación.
2. Factorización matricial
La factorización matricial es una técnica que consiste en descomponer una matriz de datos en dos matrices más pequeñas, de modo que se puedan encontrar patrones o características ocultas. Apache Mahout utiliza algoritmos como Singular Value Decomposition (SVD) y Alternating Least Squares (ALS) para realizar esta estimación.
3. Clustering
El clustering es una técnica que agrupa conjuntos de elementos similares en clusters o grupos. Apache Mahout utiliza algoritmos como K-means y Fuzzy K-means para agrupar usuarios o artículos similares, lo que permite estimar las preferencias de los usuarios en función de los grupos a los que pertenecen.
Estos son solo algunos ejemplos de los algoritmos y técnicas utilizados por Apache Mahout para estimar las preferencias de los usuarios. Cada uno de ellos tiene sus propias ventajas y desventajas, y es importante comprender cómo funcionan para elegir la mejor opción según el caso de uso.
Cómo se puede aplicar Apache Mahout en diferentes industrias y sectores
Apache Mahout es una biblioteca de aprendizaje automático que se puede aplicar en una amplia variedad de industrias y sectores. Su flexibilidad y escalabilidad hacen que sea una herramienta poderosa para estimar las preferencias de los usuarios en diferentes entornos.
En la industria del comercio electrónico, Apache Mahout puede ser utilizado para realizar recomendaciones personalizadas a los clientes. Utilizando algoritmos de filtrado colaborativo, Mahout puede analizar el comportamiento de compra de los usuarios y sugerir productos relacionados o complementarios que podrían interesarles.
En el ámbito de los servicios financieros, Apache Mahout puede utilizarse para realizar análisis de riesgo y detección de fraudes. Con su capacidad para procesar grandes volúmenes de datos, Mahout puede identificar patrones sospechosos y alertar a las instituciones financieras sobre posibles actividades fraudulentas.
En la industria de la salud, Apache Mahout puede ser utilizado para ayudar en el diagnóstico médico. Utilizando algoritmos de clasificación, Mahout puede analizar datos clínicos y generar recomendaciones para el tratamiento de enfermedades o condiciones médicas específicas.
En el sector de la publicidad en línea, Apache Mahout puede ser utilizado para mejorar la segmentación de audiencia. Utilizando algoritmos de clustering, Mahout puede agrupar a los usuarios en diferentes segmentos según sus preferencias y comportamiento en línea, lo que permite a los anunciantes llegar de manera más efectiva a su audiencia objetivo.
Estos son solo algunos ejemplos de cómo se puede aplicar Apache Mahout en diferentes industrias y sectores. Su versatilidad y capacidad para manejar grandes volúmenes de datos lo convierten en una herramienta valiosa para estimar las preferencias de los usuarios y tomar decisiones basadas en el análisis de datos.
Cuáles son los beneficios de utilizar Apache Mahout para la estimación de preferencias de los usuarios
Apache Mahout es una biblioteca de aprendizaje automático distribuido y de código abierto que proporciona una amplia gama de algoritmos para la estimación de preferencias de los usuarios. La principal ventaja de utilizar Mahout es su capacidad para procesar grandes volúmenes de datos, permitiendo a las empresas encontrar patrones y realizar recomendaciones personalizadas de manera eficiente.
Además, Mahout ofrece una serie de algoritmos de recomendación, como filtrado colaborativo y factorización de matrices, que permiten predecir las preferencias de los usuarios en función de sus patrones de comportamiento y preferencias anteriores.
Otro beneficio clave de Mahout es su capacidad para integrarse fácilmente con otras herramientas y bibliotecas de Apache, como Hadoop y Spark. Esto permite a las organizaciones aprovechar la potencia del procesamiento distribuido y paralelo para acelerar la estimación de preferencias y generar recomendaciones más precisas.
Además, Mahout ofrece una interfaz intuitiva y fácil de usar que simplifica el proceso de implementación y configuración de los algoritmos de estimación de preferencias. Esto hace que sea una opción ideal tanto para expertos en aprendizaje automático como para desarrolladores que están empezando en este campo.
Apache Mahout ofrece una serie de beneficios significativos para la estimación de preferencias de los usuarios, incluyendo el procesamiento eficiente de grandes volúmenes de datos, algoritmos de recomendación avanzados, integración con otras herramientas de Apache y una interfaz fácil de usar. Si estás buscando mejorar la personalización de tus recomendaciones y optimizar la experiencia del usuario, Mahout es una excelente opción a considerar.
Cuáles son algunos ejemplos de aplicaciones exitosas de Apache Mahout en la estimación de preferencias de los usuarios
Apache Mahout es una biblioteca de aprendizaje automático de código abierto que se utiliza para el procesamiento y análisis de grandes conjuntos de datos. Una de las aplicaciones más comunes de Mahout es la estimación de preferencias de los usuarios en diferentes ámbitos, como las recomendaciones de productos en línea o la personalización del contenido en plataformas de streaming.
En el ámbito del comercio electrónico, Apache Mahout ha demostrado ser extremadamente útil para empresas como Amazon, que utilizan algoritmos de recomendación basados en el comportamiento del usuario para ofrecer sugerencias de productos personalizadas. Esto ha llevado a un aumento significativo en las ventas y una mayor satisfacción del cliente.
Otro ejemplo de aplicación exitosa de Mahout en la estimación de preferencias de los usuarios es en la industria de la música en línea. Plataformas como Spotify utilizan algoritmos de aprendizaje automático para analizar el historial de reproducción de un usuario y ofrecer recomendaciones de canciones y artistas similares. Esto ha permitido a Spotify retener a más usuarios y aumentar su base de suscriptores.
Además del comercio electrónico y la industria de la música, Apache Mahout también se ha utilizado con éxito en otros sectores, como la publicidad en línea, la personalización de noticias y la recomendación de contenido en redes sociales. Las aplicaciones de Mahout en la estimación de preferencias de los usuarios son amplias y van desde la recomendación de productos hasta la personalización de contenido, lo que ha llevado a resultados positivos para muchas empresas en diferentes industrias.
Cuáles son los desafíos y limitaciones de utilizar Apache Mahout para la estimación de preferencias de los usuarios
La estimación de preferencias de los usuarios es un desafío crucial en muchas aplicaciones, desde la recomendación de productos hasta la personalización de contenidos. Apache Mahout se ha convertido en una herramienta popular para abordar este problema, gracias a su capacidad para procesar grandes volúmenes de datos y generar recomendaciones precisas. Sin embargo, su uso también presenta algunos desafíos y limitaciones.
Uno de los principales desafíos es la calidad y disponibilidad de los datos. Mahout requiere de un conjunto de datos representativo y diverso para poder generar recomendaciones precisas. Si los datos son escasos o sesgados, los resultados pueden ser inexactos o poco útiles.
Otro desafío es el rendimiento y escalabilidad de Mahout. A medida que el volumen de datos aumenta, es posible que la ejecución del algoritmo se vuelva lenta e ineficiente. Además, Mahout se basa en Apache Hadoop, lo que implica que requiere de infraestructuras de Big Data para su funcionamiento, lo que puede ser costoso y complejo de implementar.
Además de los desafíos técnicos, Mahout también presenta algunas limitaciones en cuanto a la diversidad de los algoritmos de recomendación. Si bien Mahout ofrece una amplia gama de algoritmos, algunos de ellos pueden no ser adecuados para ciertos casos de uso o no generar recomendaciones lo suficientemente precisas.
Apache Mahout es una herramienta poderosa para la estimación de preferencias de los usuarios, pero también presenta desafíos y limitaciones que deben ser considerados antes de su implementación. Es importante evaluar cuidadosamente los datos disponibles, el rendimiento y escalabilidad requeridos, así como la adecuación de los algoritmos de recomendación a cada caso específico.
Existen alternativas a Apache Mahout para la estimación de preferencias de los usuarios
Cuando se trata de estimar las preferencias de los usuarios, Apache Mahout es una opción popular y ampliamente utilizada. Sin embargo, existen otras alternativas que también pueden ser consideradas en función de las necesidades y requisitos específicos del proyecto.
Una de las alternativas más conocidas es TensorFlow, una biblioteca de aprendizaje automático de código abierto desarrollada por Google. TensorFlow ofrece una amplia gama de herramientas y funciones para la estimación de preferencias de los usuarios, incluyendo algoritmos de recomendación y modelos de aprendizaje profundo.
Otra opción a considerar es scikit-learn, una biblioteca de aprendizaje automático en Python. Scikit-learn proporciona una colección de algoritmos de estimación de preferencias de usuario, como regresión lineal, bosque aleatorio y máquinas de soporte vectorial.
También está LightFM, una biblioteca de factorización de matrices en Python diseñada específicamente para sistemas de recomendación. LightFM combina el rendimiento de modelos basados en factorización de matrices con la flexibilidad y la capacidad de aprendizaje de modelos basados en contenido.
Aunque Apache Mahout es una opción popular, existen varias alternativas a considerar para la estimación de preferencias de los usuarios. La elección de la herramienta adecuada dependerá de las necesidades y objetivos específicos del proyecto.
Cuáles son algunas buenas prácticas para implementar Apache Mahout de manera efectiva en la estimación de preferencias de los usuarios
Implementar Apache Mahout de manera efectiva para estimar las preferencias de los usuarios requiere seguir algunas buenas prácticas. En primer lugar, es esencial comprender los datos de entrada y elegir el algoritmo adecuado para el caso de uso específico.
Es recomendable realizar una limpieza y preprocesamiento de los datos para eliminar ruido y outliers, así como normalizar los valores. Además, es importante dividir los datos en conjuntos de entrenamiento y prueba para evaluar el rendimiento del modelo.
Otra buena práctica es ajustar los hiperparámetros del algoritmo, como el número de vecinos más cercanos o el tamaño de las recomendaciones. Este proceso de ajuste se puede realizar utilizando técnicas como la validación cruzada o la búsqueda en cuadrícula.
Además, se debe realizar una evaluación exhaustiva del rendimiento del modelo utilizando métricas como la precisión, la exhaustividad y el área bajo la curva ROC. Esto permitirá identificar posibles mejoras en el algoritmo o en los datos de entrada.
Finalmente, es fundamental tener en cuenta la escalabilidad y eficiencia del modelo. En este sentido, se pueden utilizar técnicas como el particionamiento de datos o el uso de algoritmos distribuidos para manejar grandes volúmenes de datos y mejorar el rendimiento.
Implementar Apache Mahout de manera efectiva para estimar las preferencias de los usuarios requiere comprender los datos, elegir el algoritmo adecuado, limpiar y preprocesar los datos, ajustar los hiperparámetros, evaluar el rendimiento del modelo y considerar la escalabilidad y eficiencia. Siguiendo estas buenas prácticas, se pueden obtener recomendaciones precisas y personalizadas para los usuarios.
Cuáles son las últimas tendencias y avances en el campo de la estimación de preferencias de los usuarios utilizando Apache Mahout
La estimación de preferencias de los usuarios es un campo en constante evolución y Apache Mahout se ha convertido en una herramienta clave en este aspecto.
Con el crecimiento masivo de datos en línea, es esencial poder comprender y predecir las preferencias de los usuarios para ofrecer una experiencia personalizada y relevante.
Apache Mahout es una biblioteca de aprendizaje automático que utiliza técnicas de filtrado colaborativo y algoritmos de recomendación para estimar las preferencias de los usuarios.
Esta biblioteca proporciona una variedad de algoritmos, como k-vecinos más cercanos, factorización de matrices y filtrado colaborativo basado en elementos, que permiten a los desarrolladores crear sistemas de recomendación altamente personalizados.
La capacidad de Apache Mahout para manejar grandes volúmenes de datos y su escalabilidad lo convierten en una elección popular en la industria del aprendizaje automático.
Además, Mahout está diseñado para ser utilizado en un entorno distribuido, lo que significa que puede aprovechar la potencia de clústeres de computadoras para realizar cálculos rápidos y eficientes.
Apache Mahout es una herramienta versátil y potente para estimar las preferencias de los usuarios y mejorar la experiencia en línea.
Preguntas frecuentes (FAQ)
1. ¿Qué es Apache Mahout?
Apache Mahout es una biblioteca de software de aprendizaje automático y minería de datos que se utiliza para construir sistemas de recomendación y realizar análisis y procesamiento de grandes volúmenes de datos.
2. ¿Cómo puedo utilizar Apache Mahout?
Para utilizar Apache Mahout, debes tener conocimientos básicos de programación y aprender a utilizar su API. Puedes implementar algoritmos de aprendizaje automático en Java utilizando Mahout o utilizar las funciones predefinidas para construir sistemas de recomendación.
3. ¿Qué tipos de sistemas de recomendación puedo construir con Apache Mahout?
Apache Mahout te permite construir sistemas de recomendación basados en el contenido, colaborativos y híbridos. Puedes utilizar algoritmos como filtrado colaborativo, factorización matricial y vecinos más cercanos para generar recomendaciones personalizadas.
4. ¿Cuáles son los requisitos para utilizar Apache Mahout?
Para utilizar Apache Mahout, necesitas tener instalado Java y Apache Hadoop en tu sistema. También se recomienda tener conocimientos básicos de aprendizaje automático y minería de datos.
5. ¿Es Apache Mahout compatible con otros lenguajes de programación?
Apache Mahout está diseñado para ser utilizado con Java, pero también cuenta con una API en Scala y admite la integración con otros lenguajes de programación como Python y R a través de bibliotecas externas.
Deja una respuesta
Entradas relacionadas