Apache Mahout: Aprende a usarlo en tus proyectos de machine learning
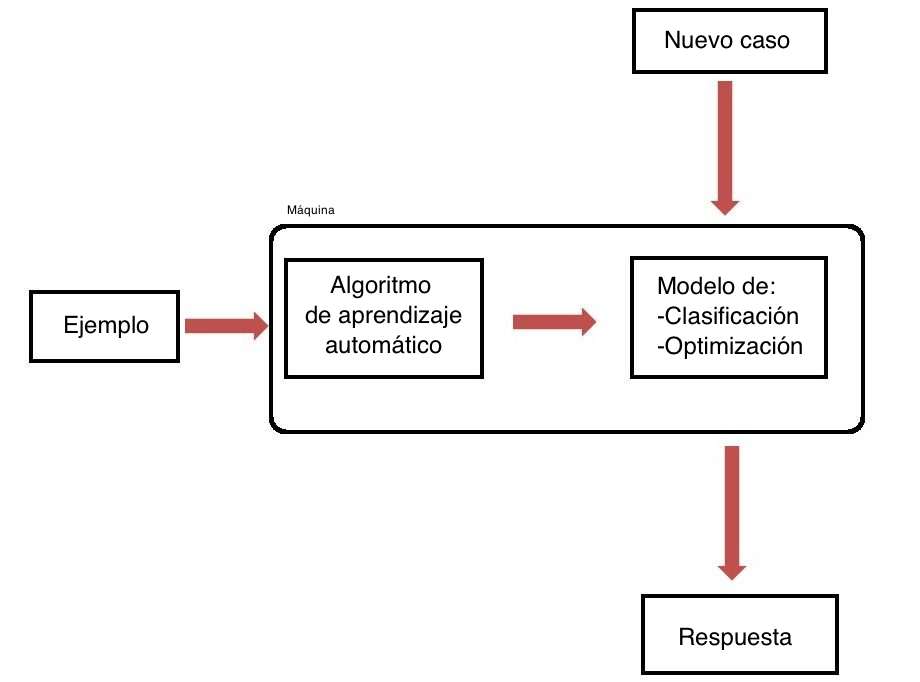
En el campo de la inteligencia artificial y el análisis de datos, el machine learning se ha convertido en una herramienta fundamental. Con el objetivo de mejorar los procesos de toma de decisiones y optimizar el rendimiento de los sistemas, cada vez más empresas y profesionales se interesan por esta disciplina. Una de las herramientas más populares y potentes para implementar algoritmos de machine learning es Apache Mahout.
Exploraremos las funcionalidades de Apache Mahout y cómo puedes utilizarlo en tus proyectos de machine learning. Desde su arquitectura hasta sus algoritmos más populares, te daremos una visión general de esta herramienta y te mostraremos cómo puedes aprovechar su potencial para obtener resultados precisos y eficientes en tus análisis de datos. Si estás buscando una solución sólida y escalable para tus proyectos de machine learning, Apache Mahout es una opción que no puedes pasar por alto.
- Cuáles son las principales características de Apache Mahout y cómo se diferencia de otras herramientas de machine learning
- En qué tipo de proyectos se puede utilizar Apache Mahout y qué beneficios puede aportar
- Cuál es la estructura básica de un proyecto de machine learning con Apache Mahout
- Cómo se pueden preparar los datos para su uso en Apache Mahout y qué técnicas de preprocesamiento se recomiendan
- Cuáles son los algoritmos de machine learning más utilizados en Apache Mahout y en qué situaciones se recomienda cada uno
- Cuál es la importancia de la validación cruzada y cómo se implementa en Apache Mahout
- Existe alguna limitación o consideración especial al utilizar Apache Mahout en proyectos de big data
- Es posible utilizar Apache Mahout en combinación con otras herramientas de machine learning, como TensorFlow o Scikit-learn
- Qué tipos de modelos de machine learning se pueden entrenar y desplegar con Apache Mahout
- Cuál es la comunidad y el soporte detrás de Apache Mahout, y cómo puedo obtener ayuda si tengo problemas o dudas
- Existen casos de éxito o ejemplos de empresas que hayan utilizado Apache Mahout en sus proyectos de machine learning
- Cuáles son las últimas novedades y actualizaciones en el desarrollo de Apache Mahout
- Preguntas frecuentes (FAQ)
Cuáles son las principales características de Apache Mahout y cómo se diferencia de otras herramientas de machine learning
Apache Mahout es una biblioteca de aprendizaje automático de código abierto que se utiliza para realizar tareas de inteligencia artificial, como la clasificación, el clustering y la recomendación. Su principal característica es su capacidad para trabajar con grandes volúmenes de datos, lo que lo convierte en una opción ideal para proyectos que requieren el procesamiento de grandes conjuntos de datos. A diferencia de otras herramientas de machine learning, Mahout se basa en la plataforma Hadoop, lo que le permite aprovechar el poder de procesamiento distribuido para realizar tareas de aprendizaje automático a gran escala.
Otra característica destacada de Apache Mahout es su interfaz de programación sencilla e intuitiva, que facilita su uso incluso para aquellos usuarios que no tienen un amplio conocimiento en programación. Esto significa que no es necesario tener experiencia en lenguajes de programación como Java o Python para empezar a utilizarlo. Mahout también cuenta con una amplia gama de algoritmos de aprendizaje automático predefinidos, lo que simplifica aún más el proceso de desarrollo de modelos de machine learning.
Además, Mahout ofrece una gran flexibilidad en cuanto a los tipos de datos que puede manejar. Puede trabajar con datos estructurados y no estructurados, lo que lo hace adecuado para proyectos que involucran diferentes tipos de datos, como texto, imágenes y vídeos. Esto lo convierte en una herramienta versátil que se puede utilizar en una amplia variedad de casos de uso, desde la clasificación de documentos hasta la recomendación de productos en sitios de comercio electrónico.
Otra ventaja de utilizar Apache Mahout en tus proyectos de machine learning es su capacidad para escalar horizontalmente. Esto significa que puedes agregar más nodos a tu clúster de Hadoop para aumentar la capacidad de procesamiento y el rendimiento de tus modelos de machine learning. Esto es especialmente útil cuando trabajas con grandes conjuntos de datos o cuando necesitas entrenar modelos complejos con millones o incluso miles de millones de ejemplos.
Apache Mahout es una herramienta poderosa y flexible para proyectos de machine learning. Con su capacidad para trabajar con grandes volúmenes de datos, su interfaz sencilla de usar y su amplia gama de algoritmos predefinidos, Mahout se destaca como una opción ideal para aquellos que desean implementar modelos de machine learning en sus proyectos de manera eficiente y efectiva.
En qué tipo de proyectos se puede utilizar Apache Mahout y qué beneficios puede aportar
Apache Mahout es una biblioteca de aprendizaje automático de código abierto que se puede utilizar en una amplia variedad de proyectos. Desde la clasificación de texto hasta la recomendación de productos, Mahout proporciona herramientas y algoritmos para abordar una variedad de problemas de aprendizaje automático.
Una de las principales ventajas de utilizar Mahout es su capacidad para manejar grandes volúmenes de datos. Al aprovechar el poder de Apache Hadoop, Mahout puede procesar y analizar conjuntos de datos masivos de manera eficiente.
Además, Mahout ofrece una amplia gama de algoritmos de aprendizaje automático que son fáciles de implementar y ajustar según las necesidades del proyecto. Esto permite a los desarrolladores experimentar y probar diferentes enfoques para encontrar el que mejor se adapte a sus necesidades.
Apache Mahout es una herramienta versátil que puede utilizarse en una amplia gama de proyectos de aprendizaje automático. Su capacidad para manejar grandes volúmenes de datos y su variedad de algoritmos hacen de Mahout una opción popular entre los desarrolladores.
Cuál es la estructura básica de un proyecto de machine learning con Apache Mahout
Un proyecto de machine learning con Apache Mahout consta de varios elementos clave. En primer lugar, se requiere una adecuada recolección y preparación de datos para su posterior análisis. Esto implica la identificación de fuentes de datos relevantes, la limpieza de datos ruidosos y la transformación de los mismos en un formato adecuado.
Una vez que los datos están listos, se procede a la fase de entrenamiento del modelo. Para ello, se utilizan algoritmos de machine learning proporcionados por Mahout, que incluyen técnicas como clustering, clasificación y recomendación.
Tras el entrenamiento, se evalúa el modelo para verificar su rendimiento utilizando métricas como la precisión, el recall y el F1-score. Esto permitirá determinar si el modelo es lo suficientemente preciso y confiable para su implementación en un entorno de producción.
Una vez que el modelo ha pasado la evaluación, se puede implementar en una aplicación o sistema interactivo. Mahout ofrece diversas opciones para la integración del modelo, como la generación de código Java o la implementación en tiempo real mediante la integración con frameworks como Apache Flink o Apache Storm.
Finalmente, se realiza un seguimiento y monitoreo continuo del modelo en producción para asegurar su correcto funcionamiento. Esto implica la recolección de datos en tiempo real, la evaluación constante del rendimiento del modelo y la actualización periódica del mismo para mejorar su precisión.
Cómo se pueden preparar los datos para su uso en Apache Mahout y qué técnicas de preprocesamiento se recomiendan
Para utilizar Apache Mahout en tus proyectos de machine learning, es importante preparar los datos adecuadamente. El preprocesamiento de datos es una etapa crucial que permite mejorar la calidad de los datos y maximizar la precisión del modelo generado.
Una de las técnicas de preprocesamiento más comunes es la limpieza de datos, que implica eliminar valores faltantes o inconsistentes, así como corregir errores de formato. Esto se puede lograr utilizando herramientas como Apache Spark o Pandas en Python.
Otra técnica importante es la normalización de datos, que consiste en escalar los valores de las características para que estén en un rango específico. Esto puede ser útil cuando las características tienen diferentes unidades o escalas.
También se recomienda aplicar técnicas de selección de características para eliminar aquellas que no aporten información relevante al modelo. Esto puede reducir la dimensionalidad de los datos y acelerar el proceso de entrenamiento.
Finalmente, es importante dividir los datos en conjuntos de entrenamiento, validación y prueba. El conjunto de entrenamiento se utiliza para entrenar el modelo, el conjunto de validación se utiliza para ajustar los hiperparámetros y el conjunto de prueba se utiliza para evaluar el rendimiento final del modelo.
Preparar los datos adecuadamente antes de utilizar Apache Mahout en tus proyectos de machine learning es fundamental para obtener resultados precisos y confiables. Asegúrate de aplicar técnicas de limpieza, normalización, selección de características y división de conjuntos de datos para maximizar el rendimiento del modelo.
Cuáles son los algoritmos de machine learning más utilizados en Apache Mahout y en qué situaciones se recomienda cada uno
En Apache Mahout, existen una amplia gama de algoritmos de machine learning disponibles para su uso en diferentes situaciones. Algunos de los más utilizados incluyen:
1. Collaborative Filtering
Este algoritmo se utiliza comúnmente en sistemas de recomendación, donde busca patrones de comportamiento entre usuarios y productos para generar recomendaciones personalizadas. Es ideal cuando se tienen grandes conjuntos de datos y se busca mejorar la experiencia del usuario.
2. Clustering
El algoritmo de clustering en Mahout permite agrupar objetos similares en diferentes categorías. Es útil cuando se desea realizar segmentación de clientes, análisis de texto y exploración de datos. Este algoritmo es escalable y permite trabajar con grandes volúmenes de datos.
3. Classification
La clasificación es un algoritmo utilizado para asignar objetos a una o varias categorías predefinidas. Se utiliza comúnmente en problemas de reconocimiento de patrones y clasificación de documentos. Mahout ofrece algoritmos como Naive Bayes y Support Vector Machine (SVM) para tareas de clasificación.
4. Regression
El algoritmo de regresión en Mahout se utiliza para predecir valores numéricos en función de variables de entrada. Se utiliza en problemas como pronósticos de ventas, precios de viviendas, entre otros. Mahout ofrece modelos de regresión lineal y regresión logística para este propósito.
5. Dimensionality Reduction
Este algoritmo se utiliza para reducir la dimensionalidad de conjuntos de datos masivos. Es útil cuando se trabaja con datos de alta dimensionalidad y se desea extraer características relevantes. Mahout proporciona técnicas como Principal Component Analysis (PCA) y Singular Value Decomposition (SVD) para esta tarea.
Apache Mahout ofrece una amplia gama de algoritmos de machine learning que se pueden utilizar en diferentes situaciones. Ya sea que estés trabajando en sistemas de recomendación, análisis de texto o clasificación de documentos, Mahout tiene algo para ofrecer. Explora estos algoritmos en tus proyectos de machine learning y aprovecha su escalabilidad y rendimiento para obtener resultados precisos y eficientes.
Cuál es la importancia de la validación cruzada y cómo se implementa en Apache Mahout
La validación cruzada es una técnica esencial en el desarrollo de modelos de machine learning, ya que nos permite evaluar la precisión y la capacidad de generalización del modelo. En Apache Mahout, esta técnica se implementa a través de la clase CrossValidator. Esta clase permite dividir los datos en k subconjuntos, y en cada iteración se entrena el modelo con k-1 subconjuntos y se evalúa con el subconjunto restante. Luego, se promedian los resultados de todas las iteraciones para obtener una evaluación más robusta del modelo. La validación cruzada en Apache Mahout es una herramienta poderosa para optimizar nuestros modelos y evitar el sobreajuste.
Cómo seleccionar el número adecuado de subconjuntos (k)
La elección del número adecuado de subconjuntos (k) en la validación cruzada es una tarea importante. Si elegimos un valor muy bajo, es posible que no obtengamos una estimación precisa del rendimiento del modelo. Por otro lado, si elegimos un valor muy alto, el tiempo de ejecución aumentará significativamente. En general, se recomienda utilizar valores entre 5 y 10 para k. Sin embargo, la elección final dependerá del tamaño y la complejidad del conjunto de datos, así como de los recursos computacionales disponibles. Por lo tanto, es importante realizar experimentos con diferentes valores de k y observar cómo afectan los resultados antes de seleccionar el número final.
El uso de la validación cruzada estratificada en Apache Mahout
La validación cruzada estratificada es una variante de la validación cruzada que se utiliza cuando se tienen datos desbalanceados o cuando queremos asegurarnos de que cada subconjunto contenga una proporción similar de cada clase. En Apache Mahout, podemos implementar la validación cruzada estratificada utilizando la clase StratifiedCrossValidator. Esta clase asegura que cada subconjunto tenga una proporción similar de clases al dividir los datos. La validación cruzada estratificada es especialmente útil en problemas de clasificación donde las clases tienen diferentes distribuciones.
Consideraciones adicionales al utilizar la validación cruzada en Apache Mahout
Al utilizar la validación cruzada en Apache Mahout, hay algunas consideraciones adicionales a tener en cuenta. En primer lugar, es importante preprocesar adecuadamente los datos y asegurarse de que estén en el formato adecuado para el algoritmo de machine learning que vamos a utilizar. Además, debemos tener en cuenta que la validación cruzada puede ser computacionalmente intensiva, especialmente si tenemos conjuntos de datos grandes. Por lo tanto, es recomendable utilizar técnicas de paralelización y distribución, como el uso de Apache Hadoop, para acelerar el proceso de validación cruzada. La validación cruzada es una técnica valiosa para evaluar y optimizar nuestros modelos de machine learning en Apache Mahout, pero debemos considerar cuidadosamente los ajustes y recursos necesarios para obtener resultados precisos y eficientes.
Existe alguna limitación o consideración especial al utilizar Apache Mahout en proyectos de big data
Al utilizar Apache Mahout en proyectos de big data, es importante tener en cuenta algunas limitaciones y consideraciones especiales. Primero, es necesario contar con un clúster de Big Data bien configurado para aprovechar al máximo las funcionalidades de Mahout. Además, es recomendable tener un buen conocimiento de algoritmos de machine learning, ya que Mahout ofrece una gran variedad de algoritmos que pueden ser aplicados en diferentes contextos.
Otra consideración importante es el tamaño y la calidad de los datos. Mahout se desarrolló para trabajar con grandes volúmenes de datos, por lo que se necesita contar con suficiente capacidad de almacenamiento y recursos computacionales para procesarlos de manera eficiente. Además, es crucial tener en cuenta la calidad de los datos, ya que cualquier ruido o inconsistencia puede afectar negativamente los resultados del modelo.
Además, es importante destacar que Mahout está diseñado para trabajar en clusters distribuidos, por lo que se requiere tener conocimientos de configuración y administración de clústeres para poder aprovechar todas las capacidades de Mahout en este entorno. Esto implica tener conocimientos en herramientas como Hadoop y Spark, que son utilizadas por Mahout para el procesamiento distribuido.
Finalmente, es relevante mencionar que Mahout se encuentra en constante desarrollo y evolución, por lo que es recomendable mantenerse actualizado con las últimas versiones y nuevas funcionalidades. La comunidad de Mahout es activa y ofrece soporte a través de listas de correo y foros, lo que puede ser de gran ayuda al enfrentar desafíos o resolver problemas en el uso de Mahout en proyectos de big data.
Es posible utilizar Apache Mahout en combinación con otras herramientas de machine learning, como TensorFlow o Scikit-learn
Apache Mahout es una biblioteca de machine learning distribuida y escalable que se puede utilizar junto con otras herramientas populares como TensorFlow o Scikit-learn. Esto permite a los desarrolladores aprovechar las fortalezas de cada una de estas herramientas y combinarlas para crear soluciones de machine learning más potentes y eficientes.
Por ejemplo, al combinar Apache Mahout con TensorFlow, se pueden utilizar las capacidades de procesamiento distribuido de Mahout para entrenar y ejecutar modelos de TensorFlow a gran escala. Esto puede ser especialmente útil cuando se trabaja con conjuntos de datos masivos que requieren un procesamiento paralelo y distribuido para lograr tiempos de entrenamiento y predicción más rápidos.
De manera similar, al combinar Apache Mahout con Scikit-learn, se pueden aprovechar las amplias capacidades de aprendizaje automático de Scikit-learn junto con las funcionalidades distribuidas y escalables de Mahout. Esto puede ser útil cuando se necesita entrenar y ejecutar modelos de aprendizaje automático en entornos distribuidos sin tener que preocuparse por la infraestructura subyacente.
La combinación de Apache Mahout con otras herramientas de machine learning proporciona a los desarrolladores una mayor flexibilidad y potencia para abordar desafíos de machine learning complejos. Además, la comunidad de Apache Mahout continúa mejorando y expandiendo las capacidades de la biblioteca, lo que la convierte en una opción sólida para aquellos que deseen utilizarla en sus proyectos de machine learning.
Qué tipos de modelos de machine learning se pueden entrenar y desplegar con Apache Mahout
Apache Mahout es una poderosa biblioteca de aprendizaje automático de código abierto que permite a los desarrolladores entrenar y desplegar una variedad de modelos de machine learning. Al utilizar Mahout, los desarrolladores pueden crear modelos de regresión, clasificación, agrupamiento, recomendación y filtrado colaborativo, entre otros.
Con Mahout, los desarrolladores también pueden entrenar y desplegar modelos de machine learning distribuidos, lo que les permite manejar grandes conjuntos de datos de manera eficiente y escalable. Esto es especialmente útil en proyectos donde el rendimiento y la escalabilidad son críticos.
Además, Mahout proporciona una amplia gama de algoritmos de aprendizaje automático, como Random Forest, K-means, Naive Bayes, support vector machines (SVM) y varios otros. Esto brinda a los desarrolladores la flexibilidad de elegir el algoritmo más adecuado para su problema específico.
Agrupamiento y recomendación
Aparte de los modelos de regresión y clasificación, Mahout también es capaz de crear modelos de agrupamiento, lo que permite agrupar datos similares en diferentes clústeres. Esto es útil en problemas como la segmentación de clientes o la identificación de patrones en datos no etiquetados.
Además, Mahout ofrece funciones de recomendación, lo que permite a los desarrolladores crear sistemas de recomendación basados en el comportamiento pasado de los usuarios. Esto es útil en aplicaciones como la recomendación de películas o productos en línea.
Modelos distribuidos y escalables
Una de las características más poderosas de Apache Mahout es su capacidad para entrenar y desplegar modelos de machine learning distribuidos. Esto significa que los desarrolladores pueden aprovechar la capacidad de procesamiento de múltiples nodos en un clúster para entrenar modelos en grandes conjuntos de datos de manera eficiente y escalable.
Al utilizar Mahout en un entorno distribuido, los desarrolladores pueden reducir significativamente el tiempo de entrenamiento de los modelos, lo que les permite experimentar y mejorar más rápidamente sus algoritmos de machine learning.
Además, Mahout también integra importantes tecnologías de big data, como Apache Hadoop y Apache Spark, lo que permite a los desarrolladores aprovechar estas tecnologías para el procesamiento y análisis eficiente de grandes conjuntos de datos.
Apache Mahout es una herramienta poderosa para entrenar y desplegar modelos de machine learning en una variedad de problemas. Con su amplia gama de algoritmos y su capacidad de procesamiento distribuido, Mahout ofrece a los desarrolladores la flexibilidad y escalabilidad necesarias para construir soluciones de machine learning robustas y eficientes.
Cuál es la comunidad y el soporte detrás de Apache Mahout, y cómo puedo obtener ayuda si tengo problemas o dudas
Apache Mahout cuenta con una comunidad activa y comprometida que brinda soporte a los usuarios. Puedes unirte a la lista de correo de Mahout para interactuar con otros usuarios y desarrolladores, hacer preguntas y obtener respuestas. Además, puedes utilizar los foros de Apache Mahout para acceder a documentación y tutoriales útiles.
Si tienes problemas o dudas específicas, puedes buscar en el archivo de la lista de correo o en los foros para ver si alguien más ha tenido un problema similar y ha encontrado una solución. También puedes publicar tu problema o pregunta en la lista de correo o en los foros y esperar que algún miembro de la comunidad te ayude.
Otra forma de obtener ayuda es participar en eventos y conferencias relacionados con Apache Mahout. Estos eventos suelen contar con expertos que pueden brindarte asesoramiento y soluciones a problemas específicos.
Lista de correo de Apache Mahout
Puedes unirte a la lista de correo de Apache Mahout enviando un correo electrónico a mahout-subscribe@apache.org. Una vez que te hayas suscrito a la lista, recibirás los mensajes enviados por otros miembros de la comunidad y podrás participar en las discusiones.
Foros de Apache Mahout
Los foros de Apache Mahout te permiten obtener respuestas a tus preguntas y encontrar soluciones a los problemas que puedas encontrar al utilizar Mahout. Puedes acceder a los foros en https://mahout.apache.org/forums/.
Eventos y conferencias
Participar en eventos y conferencias relacionados con Apache Mahout es otra forma de obtener ayuda y aprender más sobre el uso de esta herramienta en tus proyectos de machine learning. Estos eventos suelen contar con expertos que pueden brindarte asesoramiento y resolver tus dudas.
Existen casos de éxito o ejemplos de empresas que hayan utilizado Apache Mahout en sus proyectos de machine learning
Sí, existen varios casos de éxito en los que empresas han utilizado Apache Mahout en sus proyectos de machine learning. Un ejemplo es Netflix, que utiliza Mahout para su sistema de recomendación de películas y series. Otro ejemplo es LinkedIn, que utiliza Mahout para el filtrado colaborativo en su plataforma.
Otra empresa que ha utilizado Mahout es Twitter, que utiliza esta herramienta para mejorar la relevancia de los tweets en su línea de tiempo. Además, IBM también ha utilizado Mahout en sus proyectos de machine learning, especialmente en el análisis de grandes volúmenes de datos para identificar patrones y tendencias.
Estos ejemplos demuestran cómo Apache Mahout puede ser utilizado en diferentes industrias y aplicaciones, brindando soluciones efectivas para problemas de machine learning.
Cuáles son las últimas novedades y actualizaciones en el desarrollo de Apache Mahout
Apache Mahout es una potente herramienta de machine learning que continúa evolucionando con el objetivo de ofrecer a los desarrolladores nuevas funcionalidades y mejoras en su rendimiento. En este artículo, te presentaremos las últimas novedades y actualizaciones en el desarrollo de Apache Mahout, para que puedas estar al día de todas las mejoras y aprovechar al máximo esta herramienta en tus proyectos de machine learning.
Una de las últimas novedades en Apache Mahout es la incorporación de nuevos algoritmos de machine learning, que permiten abordar una mayor diversidad de problemas y mejorar la precisión de los modelos generados. Algunos de estos nuevos algoritmos incluyen algoritmos de clustering, clasificación y recomendación, entre otros.
Otra de las actualizaciones más importantes en Apache Mahout es la mejora en la escalabilidad y el rendimiento. Gracias a esto, ahora es posible trabajar con conjuntos de datos más grandes y entrenar modelos de machine learning más complejos de manera más eficiente. Esto abre nuevas posibilidades para aplicaciones que requieren el procesamiento de grandes volúmenes de datos.
Además, Apache Mahout ha mejorado su integración con otras herramientas y frameworks de machine learning, como Apache Spark, lo que permite combinar la potencia de ambos para obtener resultados aún más precisos y eficientes. Esta integración facilita el procesamiento distribuido de los datos y el entrenamiento de modelos en entornos escalables.
En cuanto a la usabilidad, Apache Mahout ha trabajado en ofrecer una interfaz más amigable y accesible para los usuarios. Ahora es más sencillo utilizar y configurar los algoritmos de machine learning, lo que agiliza el proceso de desarrollo y experimentación con diferentes técnicas. Además, se ha mejorado la documentación y se han añadido ejemplos de código que ayudan a los desarrolladores a comprender y utilizar correctamente las funcionalidades de Apache Mahout.
Las últimas novedades y actualizaciones en el desarrollo de Apache Mahout se centran en mejorar la diversidad de algoritmos disponibles, la escalabilidad y el rendimiento, la integración con otras herramientas y la usabilidad. Estas mejoras hacen de Apache Mahout una herramienta aún más poderosa y versátil para el desarrollo de proyectos de machine learning.
Preguntas frecuentes (FAQ)
1. ¿Qué es Apache Mahout?
Apache Mahout es una biblioteca de Java para el aprendizaje automático distribuido. Ofrece algoritmos y herramientas para el procesamiento de grandes volúmenes de datos y la creación de modelos de machine learning.
2. ¿Cuáles son los requisitos para usar Apache Mahout?
Para utilizar Apache Mahout, es necesario tener conocimientos básicos de Java y del entorno de desarrollo Java (IDE). También se recomienda tener experiencia en el manejo de bases de datos y en el uso de algoritmos de aprendizaje automático.
3. ¿Qué algoritmos de aprendizaje automático ofrece Apache Mahout?
Apache Mahout ofrece una amplia gama de algoritmos de aprendizaje automático, incluyendo clustering, clasificación, regresión, recomendación y filtrado colaborativo.
4. ¿Puedo utilizar Apache Mahout con otros lenguajes de programación?
Apache Mahout está diseñado para ser utilizado con Java, pero también se puede integrar con otros lenguajes de programación a través de interfaces y bibliotecas adicionales.
5. ¿Cómo puedo empezar a usar Apache Mahout en mis proyectos?
Para comenzar a utilizar Apache Mahout en tus proyectos, puedes seguir la documentación oficial y explorar los tutoriales y ejemplos disponibles en línea. También es recomendable unirse a la comunidad de Apache Mahout para obtener soporte y compartir tus experiencias con otros usuarios.
Deja una respuesta
Entradas relacionadas